# 本文以浦东新区为例--其他区自行举一反三
import requests
import pandas as pd
import pprint
import csv
import pandas as pd
from bs4 import BeautifulSoup
url=‘https://sh.lianjia.com/chengjiao/{areo}/pg{page}/‘
data=[]
#定义区列表
arealist=[‘beicai‘,‘biyun‘,‘caolu‘,‘chuansha‘,‘datuanzhen‘,‘geqing‘,‘gaohang‘,‘gaodong‘,‘huamu‘,
‘hangtou‘,‘huinan‘,‘jinqiao‘,‘jinyang‘,‘kangqiao‘,‘lujiazui‘,‘laogangzhen‘,‘lingangxincheng‘,
‘lianyang‘,‘nichengzhen‘,‘nanmatou‘,‘sanlin‘,‘shibo‘,‘shuyuanzhen‘,‘tangqiao‘,‘tangzhen‘,‘waigaoqiao‘,
‘wanxiangzhen‘,‘weifang‘,‘xuanqiao‘,‘xinchang‘,‘yuqiao1‘,‘yangdong‘,‘yuanshen‘,‘yangjing‘,
‘zhangjiang‘,‘zhuqiao‘,‘zhoupu‘]
for j in range (1,101):
for a in arealist:
houseurl=url.format(areo=a,page=j)
res=requests.get(houseurl)
res.encoding=‘utf-8‘
soup=BeautifulSoup(res.text,‘html.parser‘)
content=soup.select(‘.info‘)
# print(content)
# print (type(content))
for element in content:
datum={}
try:
title=element.select(‘.title‘)[0].text
except:
title=‘‘
try:
houseinfo=element.select(‘.houseInfo‘)[0].text
except:
houseinfo=‘‘
try:
dealDate=element.select(‘.dealDate‘)[0].text
except:
houseinfo=‘‘
try:
positionInfo=element.select(‘.positionInfo‘)[0].text
except:
positionInfo=‘‘
try:
unitPrice=element.select(‘.unitPrice‘)[0].text
except:
unitPrice=‘‘
try:
showprice=element.select(‘.dealCycleTxt‘)[0].text
except:
showprice=‘‘
try:
totalPrice=element.select(‘.totalPrice‘)[0].text
except:
totalPrice=‘‘
try:
metroline=element.select(‘.dealHouseTxt‘)[0].text
except:
metroline=‘‘
datum[‘title‘]=title
datum[‘metroline‘]=metroline
datum[‘houseinfo‘]=houseinfo
datum[‘dealDate‘]=dealDate
datum[‘positionInfo‘]=positionInfo
datum[‘unitPrice‘]=unitPrice
datum[‘showprice‘]=showprice
datum[‘totalPrice‘]=totalPrice
datum[‘page‘]=j
datum[‘area‘]=‘pudong‘ #属于哪个区放进去
datum[‘mingxi‘]=a #区下面的具体街道
data.append(datum)
# pprint.pprint(datum)
# 保存成csv文件 df=pd.DataFrame(data) # print(data) df.head() df.to_csv(‘C/Sandra/pudong.csv‘)
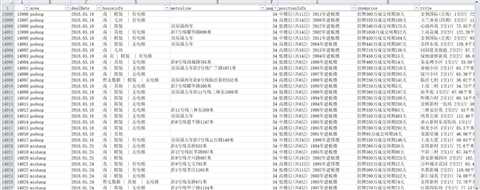
爬取下来共37636条,原始数据效果如下:
原文:https://www.cnblogs.com/260554904html/p/9043581.html