参考链接:
提取《釜山行》人物关系,
用Python的networkx绘制精美网络图
在文献计量学中,关键词的共词方法常用来确定该文献集所代表学科中各主题之间的关系。而在这里,我们需要通过分析一篇小说或剧本,来分析剧中各个角色之间的人物关系。两者有很相同的地方。
一般我们认为,在一篇文章中的同一段出现的两个人物之间,一定具有某种关联,因此我们的程序的大致流程也可以确定下来。我们可以先做分词,将每一段中的人物角色抽取出来,然后以段落为单位,统计两个角色同时出现的出现次数,并把结果存在一个二维矩阵之中。这个矩阵也可以作为关系图的矩阵,矩阵中的元素(统计的出现次数)就是边的权值。
举个例子,比如,现有三个段落的分词结果如下:a/b/c,b/a/f,a/d/c,那么就是ab共现2次,ac共现2次,以此类推。
同时,为了方便,我们把人物和人物关系也通过文件记录,我们要分析的人物关系则来自于人名的名义(小说)
jieba分词的原理和语法可以参考这篇文章《中文分词的基本原理以及jieba分词的用法》
虽然有jieba分词可以对文章进行分析,但是仍然不是很准。比如,人名名义中有一个角色叫“易学习”,“易”是副词,“学习”是动词,因此很难将这个人名分出来。不过好在结巴分词提供了自定义字典,我们就可以根据之前的分词结果,一点一点去修正自己的字典即可。当然,我建议在构建自定义字典的时候,最好先直接把人名的名义的角色表直接抄一份过来,词性全部标记成nr(人名)。
这样我们就可以通过先分词,然后筛选词性的方式,把名字筛选出来。筛选出之后,就记录到每一段的一个list中,用于后面的矩阵构成。
这个过程我们是以段落为单位进行的,因此可以设置一个全局字典来记录每一个角色的权重(即词频统计)。代码如下:
# 将剧本进行分词,并将表示人名的词提出,将其他停用词和标点省略
# 提出人名的同时,同name字典记录下来,作为矩阵的行和列
def cut_word(text):
words=pseg.cut(text)
L_name=[]
for x in words :
if x.flag!=‘nr‘ or len(x.word) < 2:
continue
if not Names.get(x.word):
Names[x.word]=1
else:
Names[x.word]=Names[x.word]+1
L_name.append(x.word)
return L_name
# 建立词频字典和每段中的人物列表
def namedict_built():
global Names
with open(‘e:/PY/relationship_find/test.txt‘,‘r‘) as f:
for l in f.readlines():
n=cut_word(l)
if len(n)>=2: # 由于要计算关系,空list和单元素list没有用
Lines.append(n)
Names=dict(sorted(Names.items(),key = lambda x:x[1],reverse = True)[:36])
# print(Line)虽然嘴上说着矩阵,但实际上在代码里使用二维字典完成的,因为这样访问起来比较快。统计也很简(bao)单(li),就是把我们在上面得出的每一段的人物list都遍历一遍。。.
由于,分词结果总是会有一些奇怪的词,所以,我们在构建矩阵的时候,直接以上面代码中的Names中的人物为基准,滤掉其他不在Names中的词,不然会有其他东西乱入。代码如下:
# 通过遍历Lines来构建贡献矩阵
def relation_built():
for key in Names:
relationships[key]={}
for line in Lines:
for name1 in line:
if not Names.get(name1):
continue
for name2 in line:
if name1==name2 or (not Names.get(name2)):
continue
if not relationships[name1].get(name2):
relationships[name1][name2]= 1
else:
relationships[name1][name2] = relationships[name1][name2]+ 1
# print(relationships)有了前面的relationships矩阵,我们就可以根据矩阵来做带权边的网络图了。这个作图方法网上教程无数,具体就不记录了,代码大概是这样:
def Graph_show():
mpl.rcParams[‘font.sans-serif‘] = [‘FangSong‘] # 指定默认字体
mpl.rcParams[‘axes.unicode_minus‘] = False # 解决保存图像是负号‘-‘显示为方块的问题
G=nx.Graph()
# 在NetworkX中,节点可以是任何哈希对象,像一个文本字符串,一幅图像,一个XML对象,甚至是另一个图或任意定制的节点对象
with open(‘e:/PY/relationship_find/edge.txt‘,‘r‘) as f:
for i in f.readlines():
line=str(i).split()
if line == []:
continue
if int(line[2])<=50:
continue
G.add_weighted_edges_from([(line[0],line[1],int(line[2]))])
nx.draw(G,pos=nx.shell_layout(G),node_size=1000,node_color = ‘#A0CBE2‘,edge_color=‘#A0CBE1‘,with_labels = True,font_size=12)
plt.show()做出来的图。。挺丑的说实话,不过好歹是个靠谱的图了
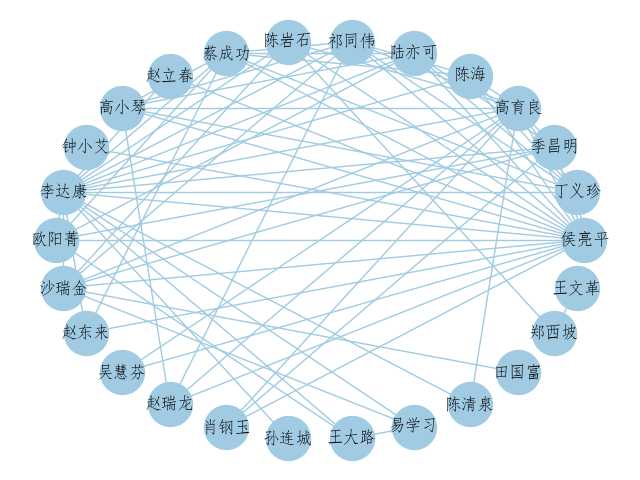
原文:https://www.cnblogs.com/August1s/p/8907251.html