切换到python 2,要加第一行才不乱码,这个是申明
name = "li\tLIlililI"
print(name.capitalize()) # 首字母大写,其他小写
print(name.casefold()) # 全部变小写,这个程序不用判断大小写
print(name.center(50))
print(name.center(50,"-"))
print(name.count("i")) #统计
print(name.count("i",3,6)) #统计从第3个开始,第6个结束
print(name.endswith("I")) # 以I结尾
print(name.expandtabs(30)) # 设置\t的长度
print(name.find("i")) # 找第一个i的位置,如果找不到就是-1
print(name.find("i",3)) # 从第3个开始找,找第一个i的位置,如果找不到就是-1
name1 = "my name is {name},i am {age} years
old"
print(name1.format(name="jensen",age=22)) #格式化输出
print(name1.format_map({"name":"lili","age":23}))
name = "li\tLIlililI"
print(name.index("li")) #找出li的索引值
print(name.isalpha()) #判断是否婴儿
name=‘2nn‘
print(name.isalnum()) # a-zA-Z0-9
print("10.1".isdecimal()) # 是否一个正整数
print("aa".isalpha()) # 是不是字母
print("a".isidentifier()) #是不是一个合法的变量名(或关键字),1a或-a都不是
print("a".islower()) # 小写
print("a".isupper()) # 大写
print("12.3".isnumeric()) #没用,不能带点
print("a".isprintable()) # 是否可打印,例如图片就不能打印,音频
print("a".isspace()) # 是不是空格
print("Ab".istitle()) # 是不是英文标题,首字母大写叫英文单词
print( ";".join(["sjse","uei","ris"])) # 把列表拼接为字符串
print(name.ljust(50,"-")) #左对齐,占50个字符,不足的话用-补充
print(name.rjust(50,"-")) #左对齐,占50个字符,不足的话用-补充
print(name.lower()) #大写变小写
print(name.rfind("n")) #用右边开始找,从左边数的位置
name1 = "my name is my {name},i am {age} years
old"
print(name1.lstrip("my")) # 移除左边第一个my
print(name1.swapcase()) # 大小写互换
# 翻译工具,容易破解,一般没人用
IN="abcde"
OUT="12345"
aaa=str.maketrans(IN,OUT)
# trans是translate是翻译
print(name1.translate(aaa)) # a变为了1
# 密码不能被破解
# 我输入密码1234
# 支付宝会变为密文adafwe
# 如果用密文输入,登录不了
print(name1.zfill(50)) #没用
print(name1.replace("s","h")) # 替换
print(name1.replace("s","h",1))#替换
# 常用的
# strip
# center
# count
# find
# casefold或lower
# upper
# join
# split
# endwith
# startwith
# replace
name3="lwlewle"
print(name3.endswith("e"))
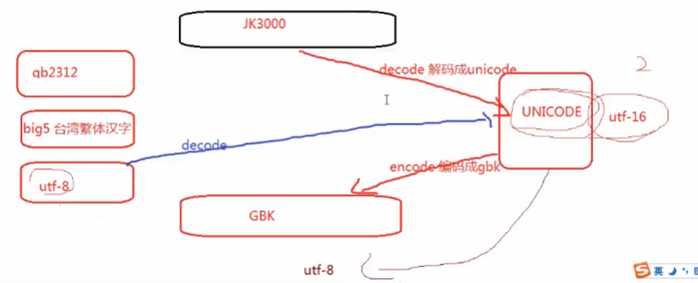
------- 编码1
# _*_ coding:utf-8 _*_
name = "中国" #utf-8 格式的编码
print name
print [name] # 存在列表里是16进制的格式的
print [name.decode("utf-8")] #你现在是什么编码
# [u‘\u4e2d\u56fd‘] 前面有u就是unicode
print name.decode("utf-8") #你看到的不是unicode,而是终端屏幕的编码格式
print name.decode("utf-8").encode("GBK") # 写要转化的目标编码
gbk = name.decode("utf-8").encode("GBK")
print gbk.decode("GBK").encode("gb2312")
print gbk.decode("GBK").encode("utf-8")
ab=gbk.decode("GBK").encode("utf-8")
print(ab)
ab1=ab.decode("utf-8").encode("GBK")
print(ab1)
# 如果内存都是unicode的话,就不会乱码
# 数据类型
# str 字符,只是一种人类可读的抽象的表示形式
# int 整数
# float 浮点
# bool 逻辑符
# list 列表
# tuple 集合
# dict 字典
# set
# bytes 字节类型,二进制类型,但不是单纯的0101,就是一个8bits的字节
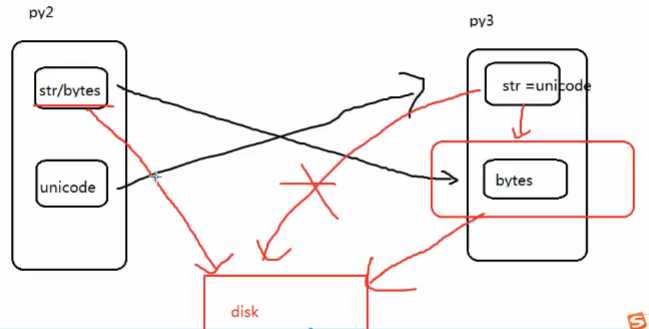
# 在python 2里,字符串都是bytes
# 在python 3里,字符串都是unicode,解释器读取文件的默认编码是utf-8,自动解码为unicode
a="jensen"
print type(bytes(a))
# python 2的str 在python 3的 python str
# str是无法直接存到硬盘的,一定要转二进制,所以转bytes
# 数据存到硬盘中或网络发送,必须是bytes形式
-- 编码2
name = "中国"
print(name)
print(type(name))
# 一些代码在liunx写的,现在要读到python 3中
# python 3 所有字符在内存里都是unicode,
# 解释器读取文件的默认编码是utf-8,自动解码为unicode
# 但有个文件的编码是gbk,读到内存里需要解码
# 打开文件
f = open ("test.txt",encoding=‘GBK‘) #默认以utf-8解释
print(f.read())
name = "中国"
print(name.encode("utf-8"))
print(name.encode("gbk")) #python3会把unicode装成相应编码的同时,把字符变成bytes