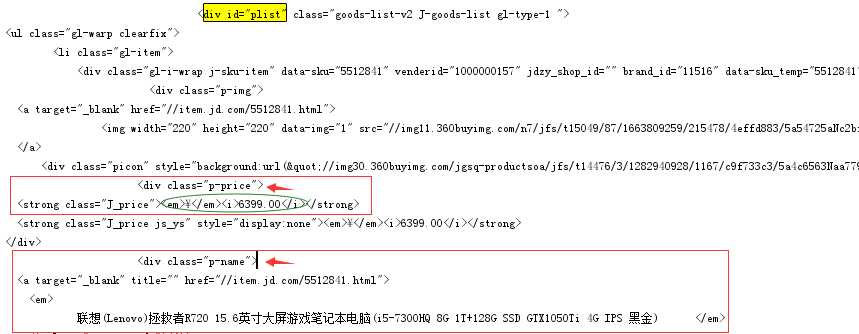
目标:扒取京东的笔记本电脑的信息(商品名和商品价格)
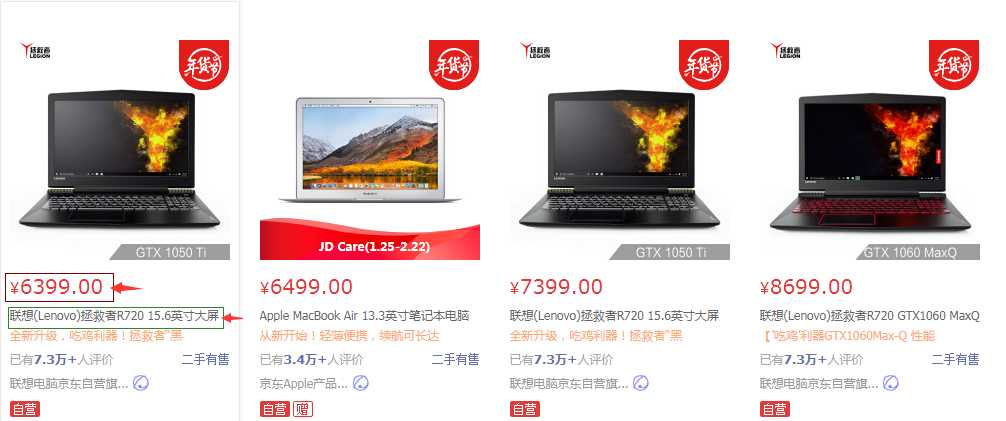
通过浏览器的开发者工具查看源代码:
一、使用urllib2获得页面源代码
1 # coding:UTF-8 2 import urllib2 3 url="https://list.jd.com/list.html?cat=670,671,672" 4 headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3298.4 Safari/537.36"} 5 request=urllib2.Request(url=url,headers=headers) 6 response=urllib2.urlopen(request) 7 html=response.read() 8 print html
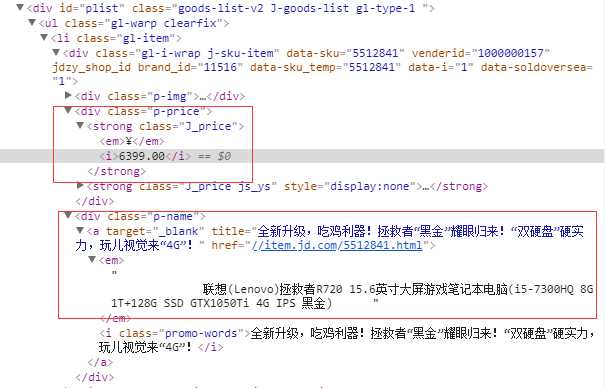
运行结果关键截图:
分析:
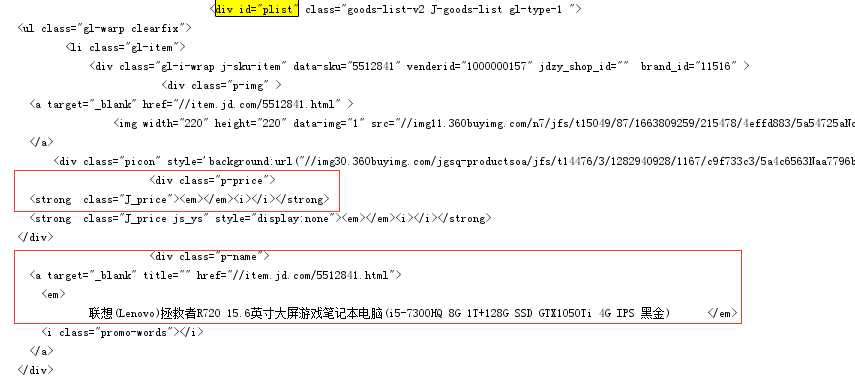
urllib2得到的源代码和通过浏览器查看的源代码不尽相同,尤其是urllib2无法得到商品的价格
二、使用selenium的webdriver得到页面源代码
from selenium import webdriver driver=webdriver.Chrome() driver.maximize_window() url="https://list.jd.com/list.html?cat=670,671,672" driver.get(url) print driver.page_source
运行结果关键截图: