之前我们做的数据爬取都是单页的现在我们来讲讲多页的
一般方式有两种目标URL循环抓取
另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源
话不多说全在代码里(因为刚才写这篇文章时电脑出现点问题所以没存下来,所以这一版本不会那么详细)
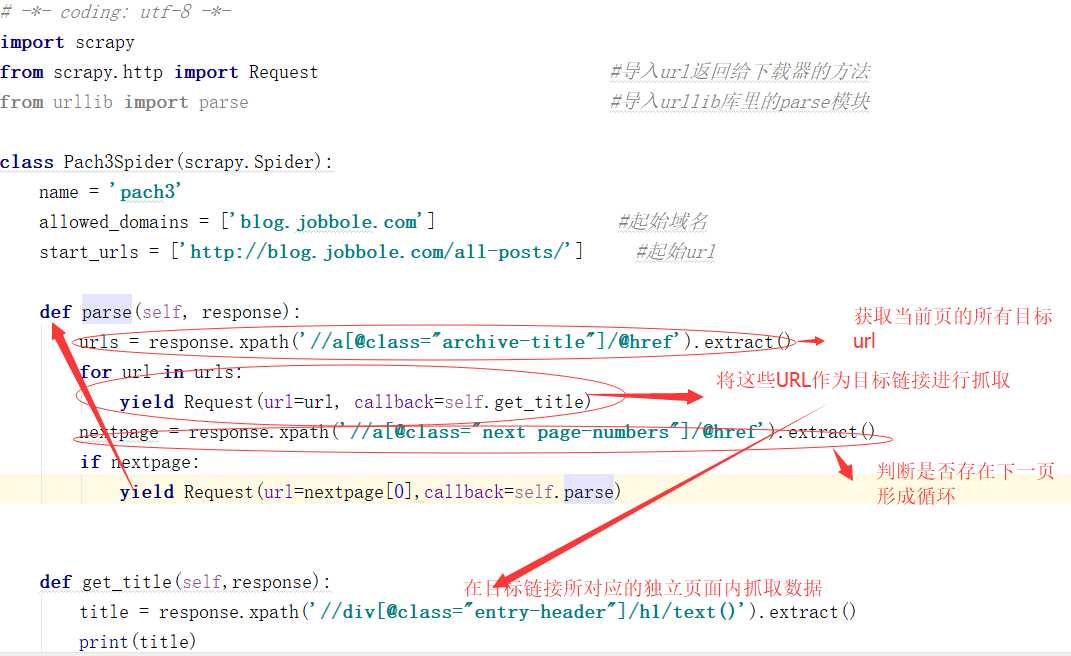
来 看下结果522*35条连接页面的数据爬取:
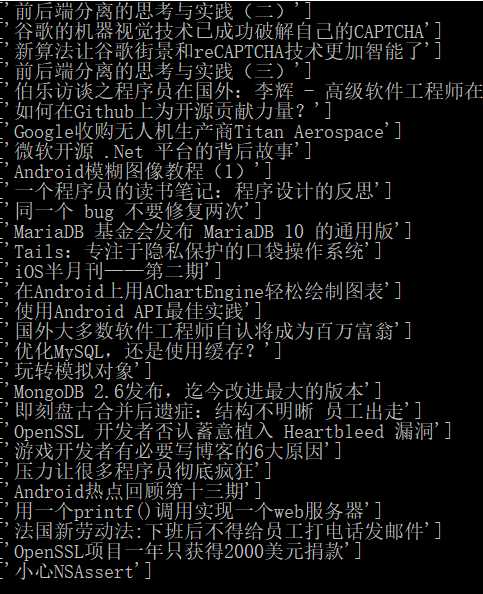
是不是很爽
之前我们做的数据爬取都是单页的现在我们来讲讲多页的
一般方式有两种目标URL循环抓取
另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源
话不多说全在代码里(因为刚才写这篇文章时电脑出现点问题所以没存下来,所以这一版本不会那么详细)
来 看下结果522*35条连接页面的数据爬取:
是不是很爽
python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
原文:https://www.cnblogs.com/woshiruge/p/8398229.html