Spring Data JPA 进行持久层(即Dao)开发一般分三个步骤:

@NoRepositoryBeanpublic interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {<S extends T> S save(S entity); //保存<S extends T> Iterable<S> save(Iterable<S> entities);//批量保存T findOne(ID id); //根据id查询一个对象boolean exists(ID id); //判断对象是否存在Iterable<T> findAll(); //查询所有的对象Iterable<T> findAll(Iterable<ID> ids);//根据id列表查询所有的对象long count(); //计算对象的总个数void delete(ID id); //根据id删除void delete(T entity); //删除对象void delete(Iterable<? extends T> entities);//批量删除void deleteAll(); //删除所有}
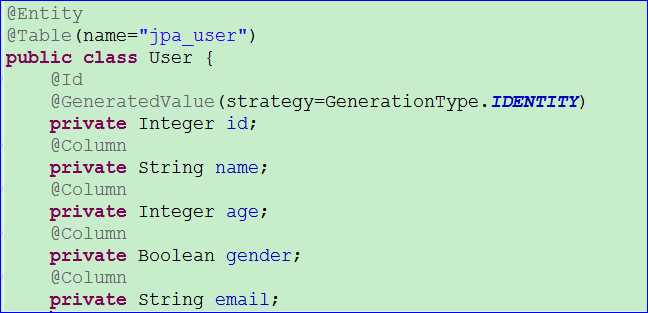

/** 测试CrudRepository的批量save方法 */@Testpublic void testCrudRepositorySaveMethod(){UserDao dao = ctx.getBean(UserDao.class);List<User> list = new ArrayList<>();for (int i = ‘A‘; i <= ‘Z‘; i++) {User u = new User();u.setName((char)i + "" + (char)i); // AA,BB这种u.setGender(true);u.setAge(i + 1);u.setEmail(u.getName() + "@163.com");list.add(u);}// 调用dao的批量保存dao.save(list);}/** 测试CrudRepository的save */@Testpublic void testCrudRepositoryUpdate(){UserDao dao = ctx.getBean(UserDao.class);// 从数据库查出来User user = dao.findOne(1);// 修改名字user.setName("Aa");dao.save(user); // 经过测试发现,有id时是更新,但不是绝对的;类似jpa的merge方法}
@NoRepositoryBeanpublic interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {Iterable<T> findAll(Sort sort); // 不带分页的排序Page<T> findAll(Pageable pageable); // 带分页的排序}

/** 测试PagingAndSortingRepositoryd的分页且排序方法 */@Testpublic void testPagingAndSortingRepository() {UserDao userDao = ctx.getBean(UserDao.class);/* 需求:查询第3页的数据,每页5条 */int page = 3 - 1; //由于springdata默认的page是从0开始,所以减1int size = 5;//Pageable 接口通常使用的其 PageRequest 实现类. 其中封装了需要分页的信息//排序相关的. Sort 封装了排序的信息//Order 是具体针对于某一个属性进行升序还是降序.Order order1 = new Order(Direction.DESC, "id");//按id降序Order order2 = new Order(Direction.ASC, "age");//按age升序Sort sort = new Sort(order1,order2);Pageable pageable = new PageRequest(page, size,sort);Page<User> result = userDao.findAll(pageable);System.out.println("总记录数: " + result.getTotalElements());System.out.println("当前第几页: " + (result.getNumber() + 1));System.out.println("总页数: " + result.getTotalPages());System.out.println("当前页面的 List: " + result.getContent());System.out.println("当前页面的记录数: " + result.getNumberOfElements());System.out.println("当前的user对象的结果如下:");for (User user : result.getContent()) {System.out.println(user.getId() + " == " + user.getAge());}}


@NoRepositoryBeanpublic interface JpaRepository<T, ID extends Serializable>extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {List<T> findAll(); //查询方法List<T> findAll(Sort sort); //查询方法,带排序List<T> findAll(Iterable<ID> ids); //查询方法,参数为id集合<S extends T> List<S> save(Iterable<S> entities); //批量保存void flush(); //刷新<S extends T> S saveAndFlush(S entity); //保存并刷新,类似merge方法void deleteInBatch(Iterable<T> entities);void deleteAllInBatch();T getOne(ID id);<S extends T> List<S> findAll(Example<S> example); //根据“example”查找,参考:http://www.cnblogs.com/rulian/p/6533109.html<S extends T> List<S> findAll(Example<S> example, Sort sort); //根据“example”查找并排序}

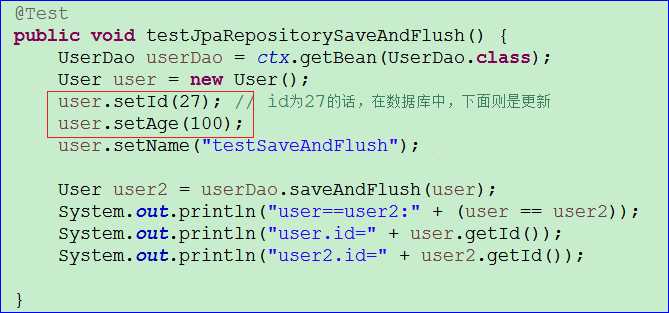
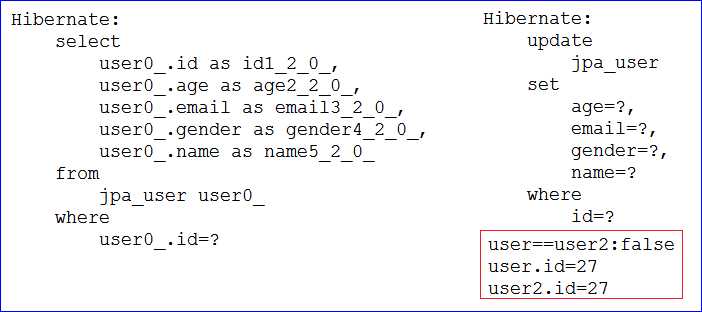
/** 测试JpaRepository的SaveAndFlush */@Testpublic void testJpaRepositorySaveAndFlush() {UserDao userDao = ctx.getBean(UserDao.class);User user = new User();user.setId(30); // id为30的话,不在数据库中。如果在数据库中,下面则是更新user.setAge(27);user.setName("testSaveAndFlush");User user2 = userDao.saveAndFlush(user);System.out.println("user==user2:" + (user == user2));System.out.println("user.id=" + user.getId());System.out.println("user2.id=" + user2.getId());}

public interface JpaSpecificationExecutor<T> {T findOne(Specification<T> spec);List<T> findAll(Specification<T> spec);Page<T> findAll(Specification<T> spec, Pageable pageable); //条件查询,且支持分页List<T> findAll(Specification<T> spec, Sort sort);long count(Specification<T> spec);}

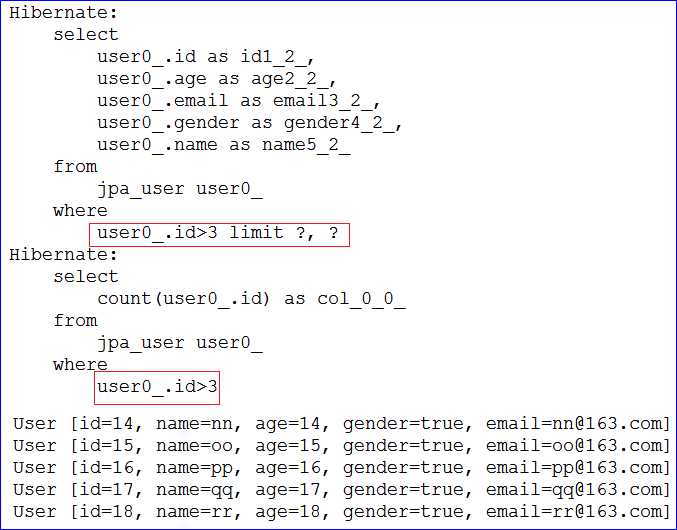
/*** 目标: 实现带查询条件的分页. id > 3 的条件* 调用 JpaSpecificationExecutor 的 Page<T> findAll(Specification<T> spec, Pageable pageable);* Specification: 封装了 JPA Criteria 查询的查询条件* Pageable: 封装了请求分页的信息: 例如 pageNo, pageSize, Sort*/@Testpublic void testJapSpecificationExecutor() {// 目标:查询id>3 的第3页的数据,页大小为5UserDao userDao = ctx.getBean(UserDao.class);Pageable pageable = new PageRequest(3 - 1, 5);//通常使用 Specification 的匿名内部类Specification<User> spec = new Specification<User>() {/*** @param root: 代表查询的实体类.* @param query: 可以从中可到 Root 对象, 即告知 JPA Criteria 查询要查询哪一个实体类. 还可以* 来添加查询条件, 还可以结合 EntityManager 对象得到最终查询的 TypedQuery 对象.* @param cb: CriteriaBuilder 对象. 用于创建 Criteria 相关对象的工厂. 当然可以从中获取到 Predicate 对象* @return: Predicate 类型, 代表一个查询条件.*/@Overridepublic Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {// 一般用root和cb就ok了return cb.gt(root.get("id"), 3);// 多条件查询的案例/*Predicate p1 = cb.notEqual(root.get("id"), 15);Predicate p2 = cb.like(root.get("email"),"%163.com");return cb.and(p1,p2);*/}};Page<User> list = userDao.findAll(spec, pageable);for (User user : list) {System.out.println(user);}}
原文:http://www.cnblogs.com/zeng1994/p/7627267.html