中文分词

b=open(‘book.txt‘,‘r‘,encoding=‘utf-8‘) book=b.read() b.close()
import jieba b=open(‘book.txt‘,‘r‘,encoding=‘utf-8‘) book=b.read() b.close() for i in ‘,。、!; )“”·)?:……[(-‘: book=book.replace(i,‘ ‘) books=jieba.cut(book) ex={‘的‘,‘他‘,‘她‘,‘地‘,‘吧‘,‘咱们‘} ke=set(books)-ex dic={} for w in ke: if len(w)>1: dic[w]=book.count(w) wc=list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(wc[i])
ex={‘的‘,‘他‘,‘她‘,‘地‘,‘吧‘,‘咱们‘}
ke=set(books)-ex
dic={}
for w in ke:
if len(w)>1:
dic[w]=book.count(w)
wc=list(dic.items())
wc.sort(key=lambda x:x[1],reverse=True)
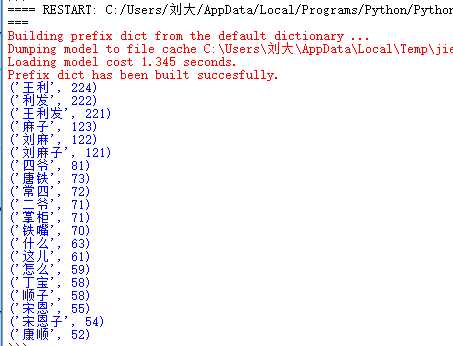
4.对词频统计结果做简单的解读。
老舍的《茶馆》,是一篇茶馆故事,主要人物为王利,围绕一些人物在茶馆发生的事……
原文:http://www.cnblogs.com/1996liuda/p/7610338.html