中文分词
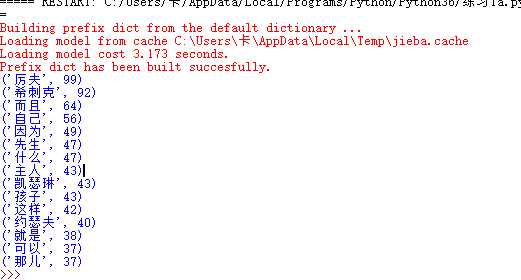
import jieba a=open(‘呼啸山庄.txt‘,‘r‘,encoding=‘utf-8‘).read() b=list(jieba.cut(a)) exp={‘我们‘,‘他们‘,‘,‘,‘。‘,‘一个‘,‘没有‘,‘可是‘,‘起来‘} keys=set(b)-exp dic={} for c in keys: if len(c)>1: dic[c]=b.count(c) d=list(dic.items()) d.sort(key=lambda x:x[1],reverse =True) for i in range (15): print(d[i])
原文:http://www.cnblogs.com/wk15/p/7610406.html