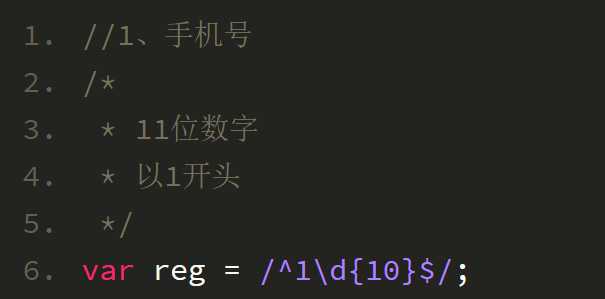
正则
一个用来处理字符串的规则,通过规则我们可以验证字符串是否匹配对应的格式(TEST),也可以把正则匹配的结果在字符串中捕获到(EXEC)
正则由两部分组成:
- 修饰符:i(ignoreCase忽略大写小匹配)、m(multilin匹配多行)、g(global全局匹配,解决正则捕获的懒惰性)
- 元字符
- 特殊元字符
- \ :转译字符
- ^:以某一个元字符开头
- $:以某一个元字符结尾
- .:除了\n(换行符)以外的任意字符
- \d:0-9之间的一个数字,等价于[0-9]
- \D:和\d相反,除了0-9之间的任意字符,所有这类情况的(\s、\b…)都有一个大写情况,也都是和本身意思相反
- \b:边界
- \s:匹配任意一个空白字符(空格和制表符)
- \w:匹配数字、字母、下划线中的任意一个,等价于[a-zA-Z0-9_]
- [xyz]:x、y、z三者中的任意一个
- [^xyz]:取反,除了x/y/x三者之外的任意字符
- [a-z]:获取范围中的任意一个字符
- [^a-z]:取反
- |:或者
- ():分组
- ?: :只匹配不捕获
- ?=:正向预查
- ?!:负向预查
- …
- 量词元字符
- *:出现零到多次
- +:出现一到多次
- ?:出现零次或者一次
- {n}:出现N次
- {n,}:出现n到多次
- {n,m}:出现n到m次
- 普通元字符:在 / / 包含起来的,除了具有特殊意义的,其余的都是代表本身意思的普通元字符
[]的一些特殊情况:
- 中括号中出现的字符,大部分都是代表本身的意思,例如:
/^[\d.]$/
\d还是0-9之间一个数字,.不是任意字符只是一个小数点
- 中括号中不识别多位数字,例如:/$/ 1或者2-4或者0,三者中的一个
()的作用:
- 改变优先级,栗如:
- /^18|29$/ 匹配18、29、182、189、829、129、1829…都符合
- /^(18|29)$/ 匹配18、29
- 分组捕获:在正则每一次捕获的时候,除了可以把大正则匹配的结果捕获到,还可以把里面小分组匹配的内容捕获到,栗如:
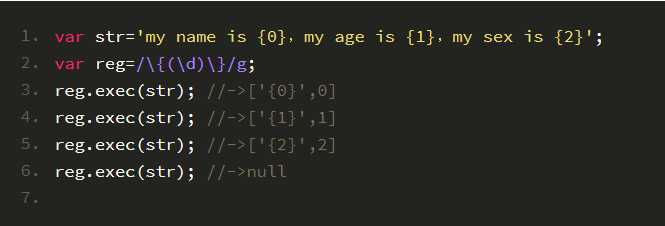
- 分组引用:\1代表和第一个分组出现一模一样的内容,\2和第二个分组出现一模一样的内容…



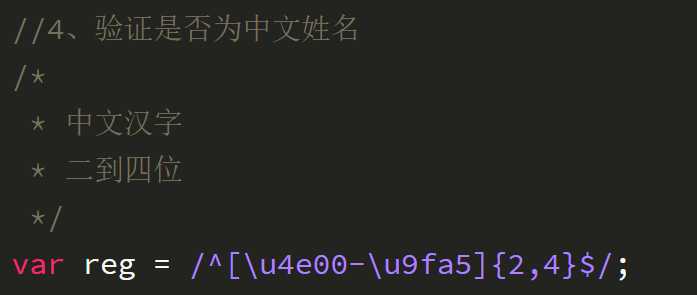
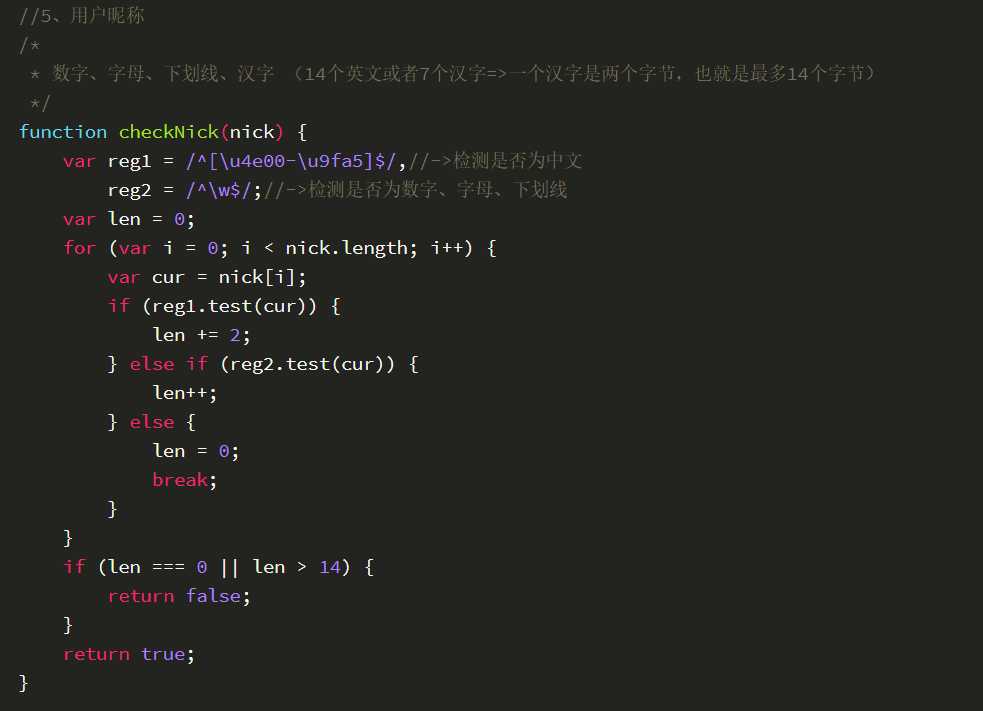

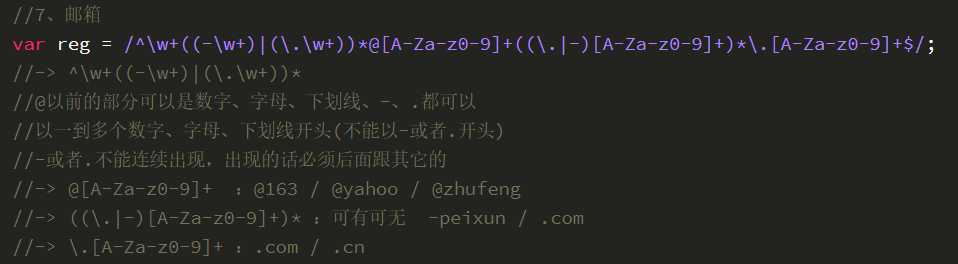

- 正则的捕获:
- 懒惰性
- 贪婪性
- test、exec、match、replace、split…大部分字符串中支持正则的方法都可以实现正则的捕获
有关正则的知识点梳理
原文:http://www.cnblogs.com/Scar007/p/7606245.html