cd 到hadoop中
然后格式化 进入到 bin下 找到 hdfs 然后看看里面有哈参数:
./hdfs namenode -format 格式化
然后启动 sbin/start-dfs.sh
hdfs的关系界面
http://192.168.94.132:50070/
创建文本:
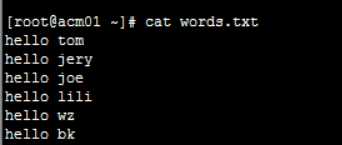
创建个目录 hdfs dfs -mkdir /wc 创建个目录
上传3份

打开spark-shell
分配下资源哦 而且不要启动单机版的 要启动集群
把 wc下面的文件都读取了 哈哈哈
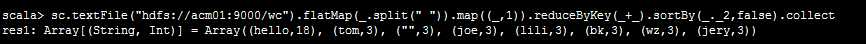
如果要保存到hdfs中去呢?

用spark shell 用scala 了
把hive 配置文件放到 spark 的conf 中 以后让 hive 直接跑在spark上面 爽了 更快
hive on spark 换了个执行引擎
------------------------------------------------------------------------------------------------------
1.首先启动hdfs
2.向hdfs上传一个文件到hdfs://node1.itcast.cn:9000/words.txt
3.在spark shell中用scala语言编写spark程序
sc.textFile("hdfs://node1.itcast.cn:9000/words.txt").flatMap(_.split(" "))
.map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://node1.itcast.cn:9000/out")
(先从hdfs中读数据 然后 读进来的数据flatMap 进行切分 压扁, map把每个元素取出来进行相应操作,生成rdd(以前都是数组或集合的方法操作),reduceBykey rdd独有的, sortBy )
4.使用hdfs命令查看结果
hdfs dfs -ls hdfs://node1.itcast.cn:9000/out/p*
原文:http://www.cnblogs.com/toov5/p/7530596.html