python的标准安装中包含标准库
import math (从默认的路径中寻找math模块)
python解释器从哪里查找模块呢?即搜索路径,目录列表可以在sys模块的paht变量中找到 ,sys.path,打印出来
import sys,pprint
pprint.pprint(sys.path) //pprint为智能打印输出

import sys
sys.path.append(‘c:/python‘) //模块路径
import hello //模块的文件名应该为hello.py
内部逻辑:导入模块的时候,会生成 modulename.pyc,.pyc文件是编译好的python能够有效处理的文件,.pyc文件会随着.py文件的更新而更新
模块只有在第一次导入到程序时被执行
1.访问模块中的函数:模块名.functionname()
2.访问模块中的变量:模块名.globalname
所有模块都有一个内置属性__name__ ,它的值取决于如何应用模块:
1.当import 一个模块,__name__=模块名
2.当运行一个模块,__name__=‘__main__‘ (默认为__main__)
if __name__==‘__main__‘: test() 可以理解为当独立运行该模块的时候(不包括被import),执行test()函数。如果该模块被导入的时候(即__name__=‘module name‘),不执行该if下面的语句,直接用模块名.方法名使用
包就是模块所在的目录,为了让python将其作为包对待,包中必须包含一个名为__init__.py的文件,(可以把它想象成模块中的构造函数,用来初始化的作用)如果访问__init__.py文件中的变量PI,则使用包名.PI即可
~/python/
~/python/drawing/ //包drawing
~/python/drawing/__init__.py //
~/python/drawing/colors.py //包模块
~/python/drawing//shapes.py //包模块
假设包放置在了python搜索路径下
import drawiing //只能用__init__模块
import drawing.colors //可独立使用,colors模块可用,通过全名drawing.colors使用
from drawing import shapes //可独立使用,shapes模块可用,通过短名shapes使用
不管是标准库还是添加的python其他功能模块,都可以用import导入进来查看里面的具体内容
打印对象的所有特性,包括函数,类,变量等,以下划线开始的过滤掉不打印

全部,包含以下划线开始的名字列表

检查__all__变量的内容:
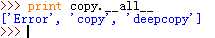
__all__=["Error","copy","deepcopy"] 定义了模块的公有接口,即执行from copy import * 后,可以使用all变量中的函数,执行copy.PyStringMap 或 from copy import PyStringMap 才可以使用PyStringMap
如果没有设定__all__,用from copy import * 后,导入所有不以下划线开头的全局名称。
------------------------------------------------------------------------------------------------------------------------------------
help(copy.copy) 帮助显示copy模块中的copy函数的用法
help(copy) 帮助显示copy模块以及模块中的更多函数信息
或
print copy.copy.__doc__ 显示copy函数的文档
http://python.org/doc/lib 在线文档
或
print copy.__file__ 查找copy模块源码文件在哪儿
C:\python27\lib\copy.py
-----------------------------------------------------------------------------------------------------------------------------------
五、常用模块
| sys模块 | |
| argv | 命令行参数,包括脚本名称 |
| exit([arg]) | 退出当前程序,可选参数为给定的返回值或错误消息 |
| modules | 映射模块名字到载入模块的字典 |
| path | 查找模块所在目录的目录名列表 |
| platform | 平台标示符 |
| stdin | 标准输入流 |
| stdout | 标准输出流 |
| stderr | 标准错误流 |
| os模块 | |
| environ | 对环境变量进行映射 |
| system(command) | 在子shell中执行操作系统命令 |
| sep | 路径中的分隔符 |
| pathsep | 分隔路径的分隔符 |
| linesep | 行分隔符(‘\n‘,‘\r‘) |
| urandom(n) | 返回n字节的加密强随机数据 |
| fileinput模块 | |
| input([files[. inplace[. backup]]) | 便于遍历多个输入流中的行 |
| filename() | 返回当前文件的名称 |
| lineno() | 返回当前(累计)的行数 |
| filelineno() | 返回当前文件的行数 |
| isstdin() | 检查最后一行是否来自sys.stdin |
| isfirstline() | 检查当前行是否是文件的第一行 |
| nextfile() | 关闭当前文件,移动到下一个文件 |
| close() | 关闭序列 |
集合、堆、双端队列
| 集合set |
a=set([1,2,3]) b=set([2,3,4]) |
|
| a.union(b) | set([1,2,3,4]) | |
| a&b | set([2,3]) | |
| a.intersection(b) | set([2,3]) | |
| a.difference(b) | set([1]) | |
| a-b | set([1]) | |
| a.symmetric_difference(b) | set([1,4]) | |
| a ^ b | set([1,4]) | |
| a.copy() | set([1,2,3]) | |
| 堆heap | 模块名是heapq | |
| heappush(heap,x) | 将x入堆 | |
| heappop(heap) | 将堆中最小的元素弹出 | |
| heapify(heap) | 将heap属性强制应用在任意一个列表 | |
| heapreplace(heap,x) | 将堆中最小的元素弹出,同时将x入堆 | |
| nlargest(n,iter) | 返回iter中第n大的元素 | |
| nsmallest(n,iter) | 返回iter中第n小的元素 | |
| 双端队列deque | from collections import deque | |
| q=deque([6,0,1,2,3,4,5]) | ||
| q.pop() | 返回5,删除5 | |
| q.popleft() | 返回6,删除6 | |
| q.rotate(3) | 右移3位,此时q=deque([2,3,4,0,1]) | |
| q.rotate(-1) | 左移1位,此时q=deque([3,4,0,1,2]) |
time模块
包含9个整数的元祖(2008,1,21,12,2,56,0,21,0)表示 “2008年1月21日12点2分56秒,星期一,当年的第21天,无夏令时”。
time.asctime() 返回‘Fri Dec 21 05:41:27 2008’
| asctime([tuple]) | 将时间元祖转换为子串 |
| loacaltime([secs]) | 将秒数转换为日期元祖,以本地时间为准 |
| mktime(tuple) | 将时间元祖转换为本地时间 |
| sleep(secs) | 休眠secs秒 |
| strptime(string[,format]) | 将字符串解析为时间元祖 |
| time() | 当前时间(新纪元开始后的秒数,以UTC为准) |
random模块
| random() | 返回0<n<=1之间的随机实数 |
| getrandbits(n) | 以长整型形式返回n个随机位 |
| uniform(a,b) |
返回随机实数n,其中a<=n<b |
| randrange([start],stop,[step]) | 返回range(start,stop,step)中的随机数 |
| choice(seq) | 从序列seq中返回随意元素 |
| shuffle(seq[,random]) | 原地指定序列seq |
| sample(seq,n) | 从序列seq中选择n个随机且独立的元素 |
shelve模块
简单的存储
省略。。。。。。。。
原文:http://www.cnblogs.com/zz27zz/p/7454667.html