一:导入 mysql--》hdfs
1.准备
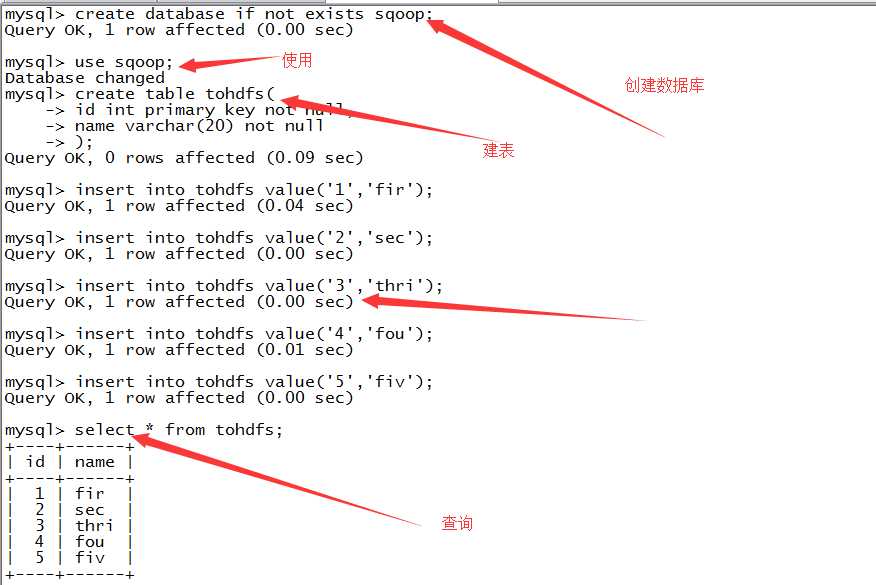
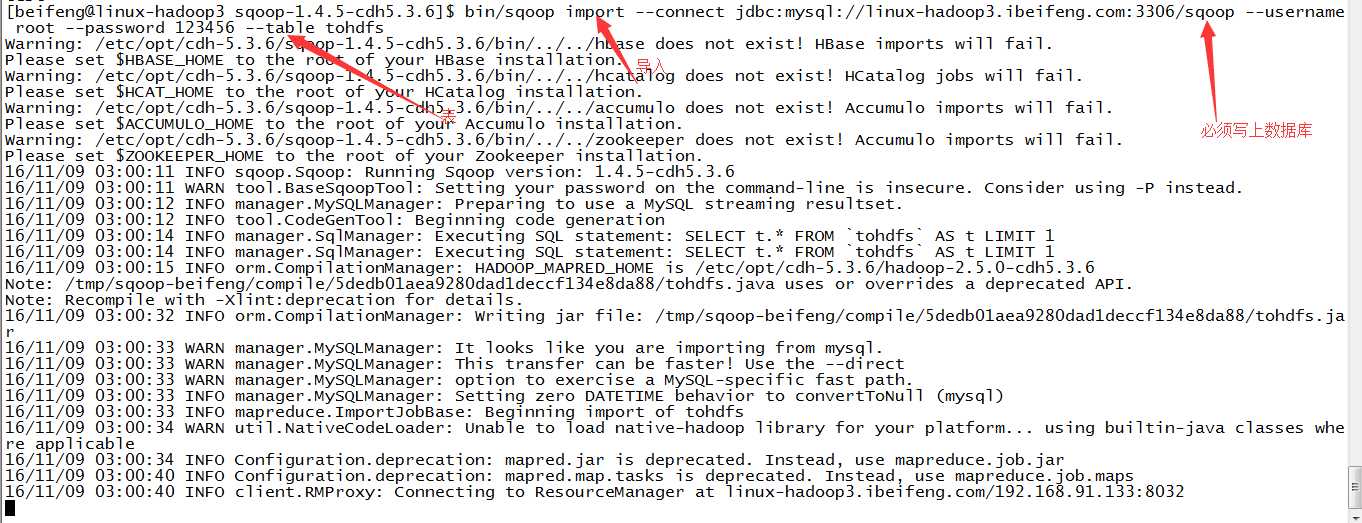
2.导入数据
可以看到在跑yarn。
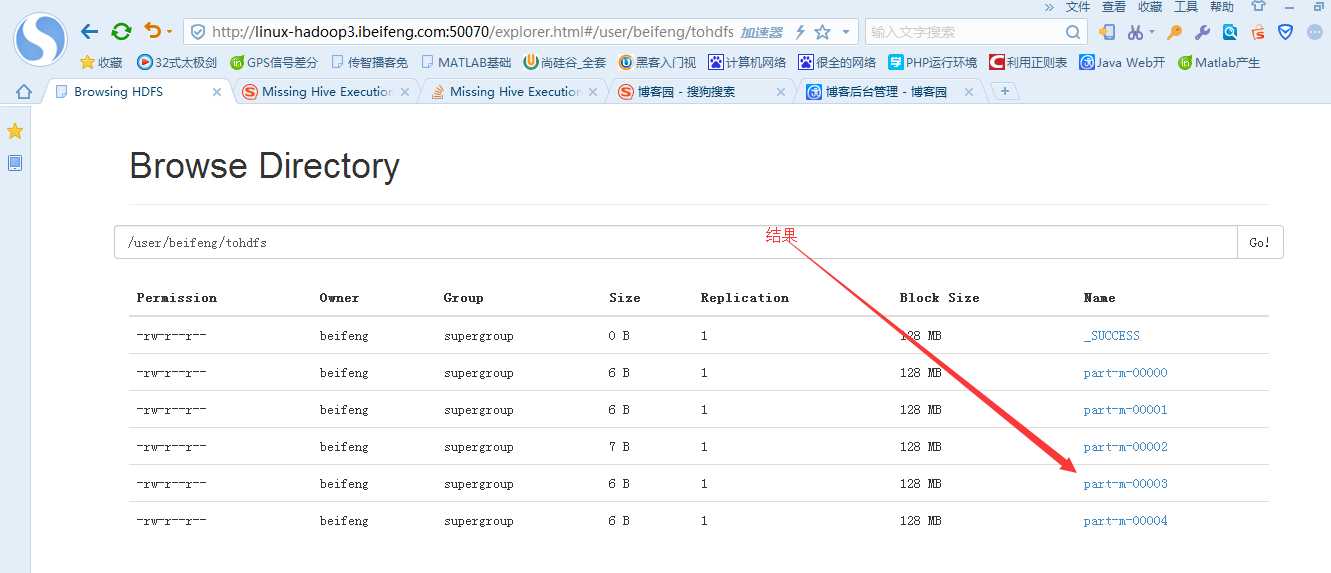
3.在HDFS上看结果
默认的地址:hdfs的家目录。
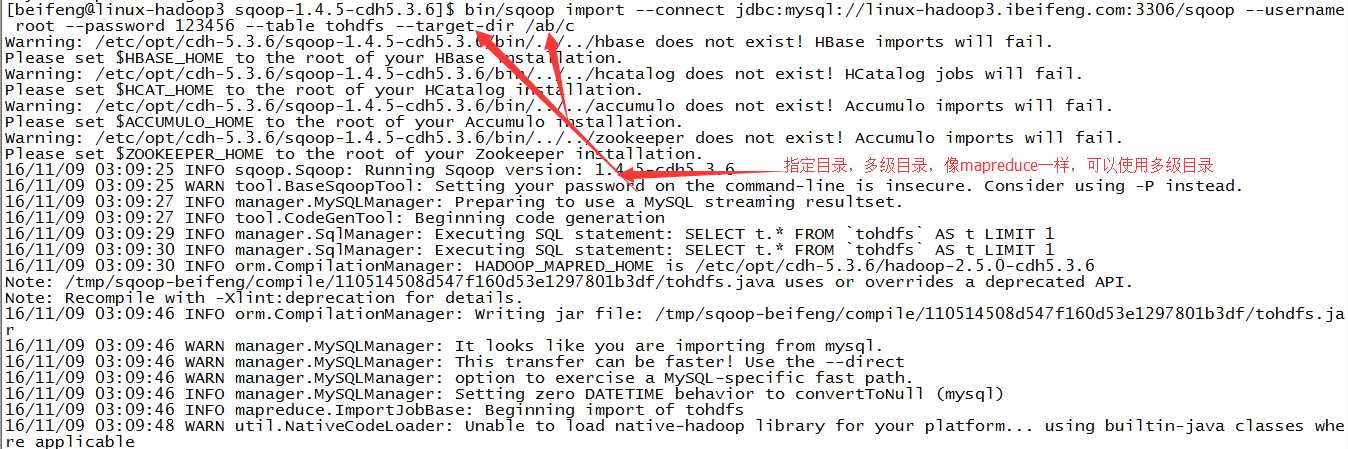
4.在HDFS上指定目录
5.指定map的个数,相同目录时,先删除原来的目录
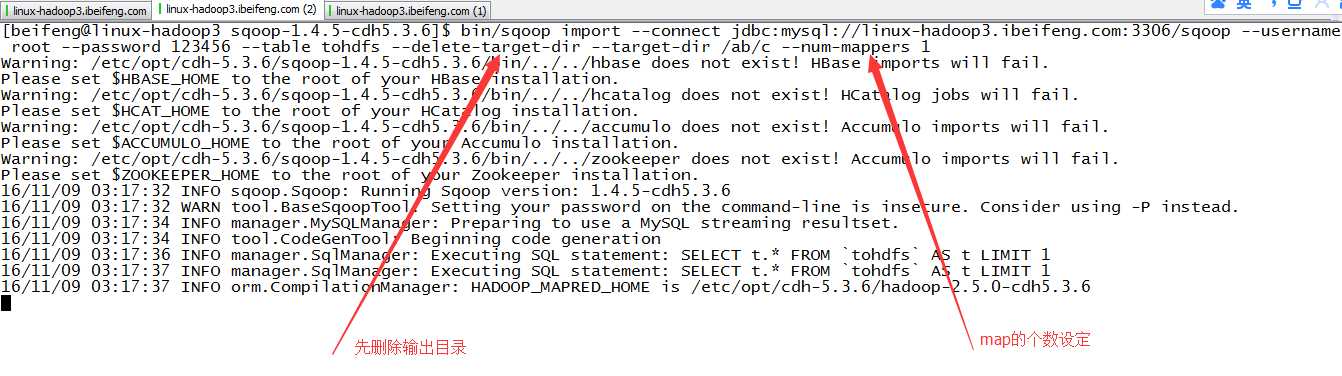
6.查看结果

7.指定分隔符
默认是‘,’,在HDFS上修改‘\t’
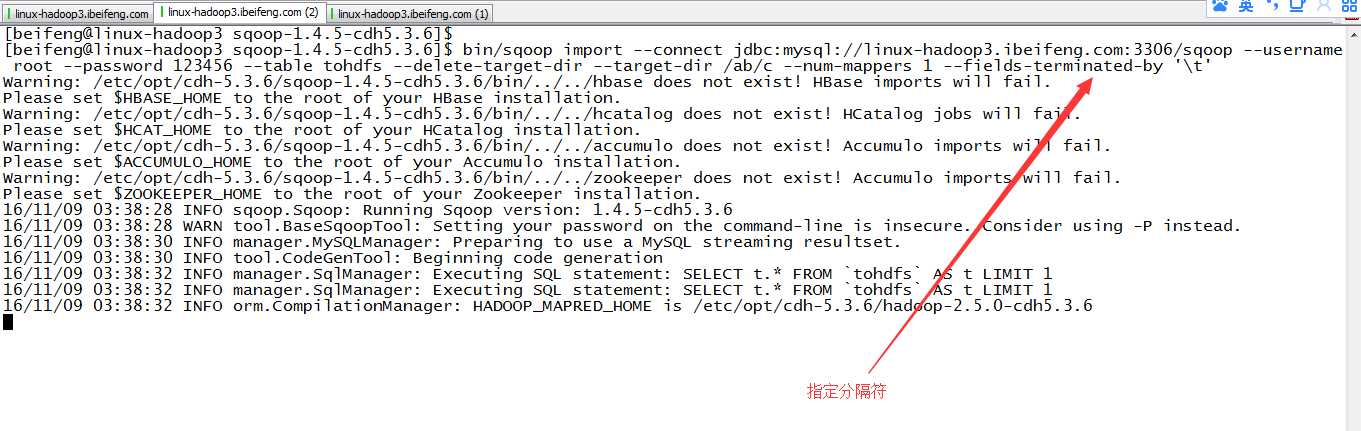
8.重新查看结果

9.更快的方式
10.增量导入之前的准备
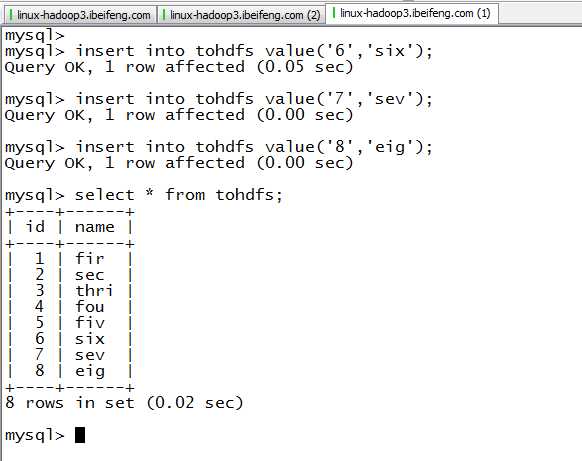
11.增量导入
在增量导入的时候,不能加上--delete---target-dir,因为这是增量导入
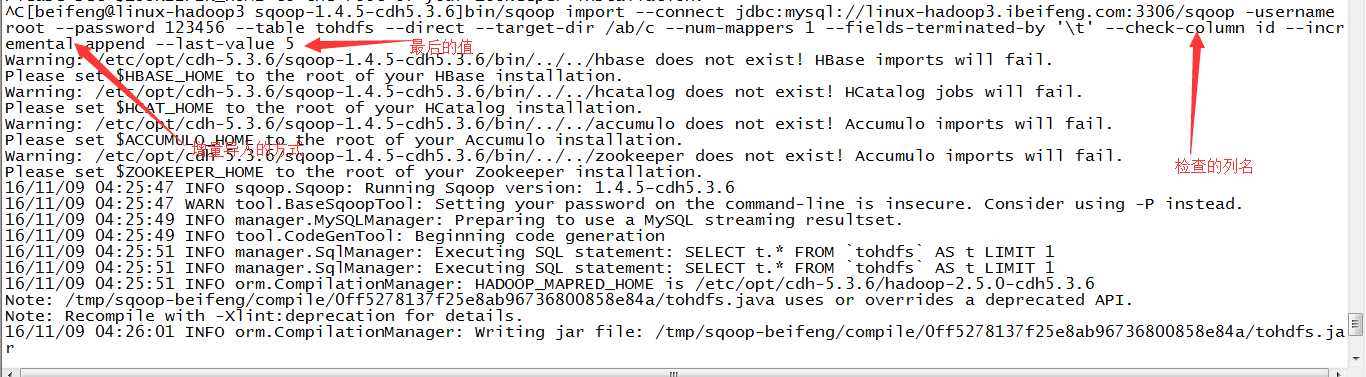
12.查看增量结果

13.创建一个job任务之前的任务

14.创建一个job任务
注意:命令为 --create
--与import之间有一个空格。

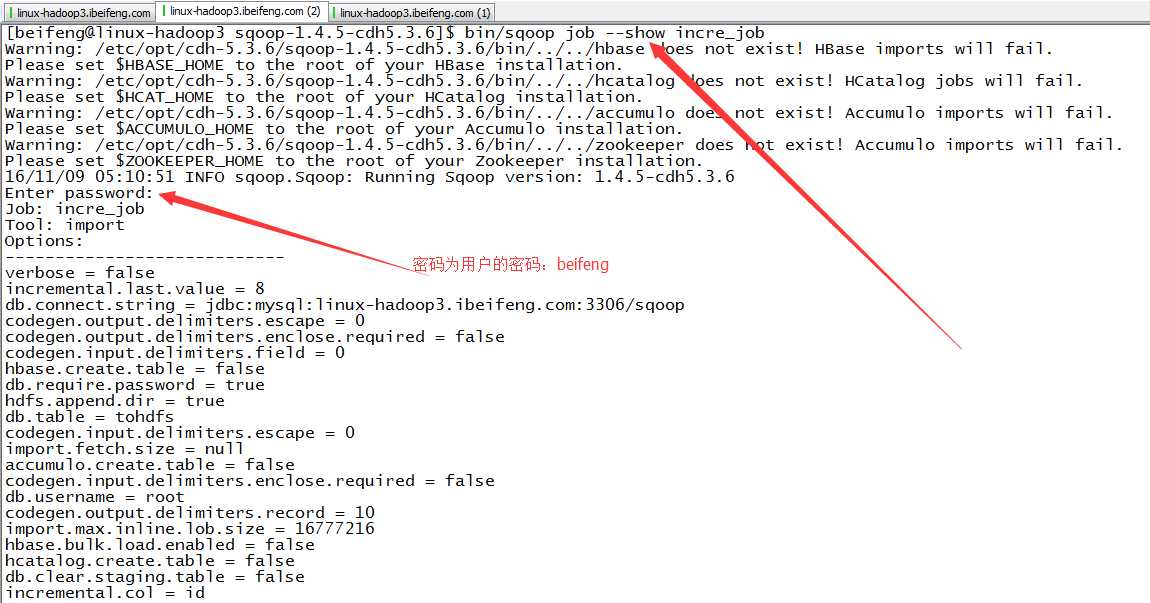
15.查看一个job

16.查看job的详细信息
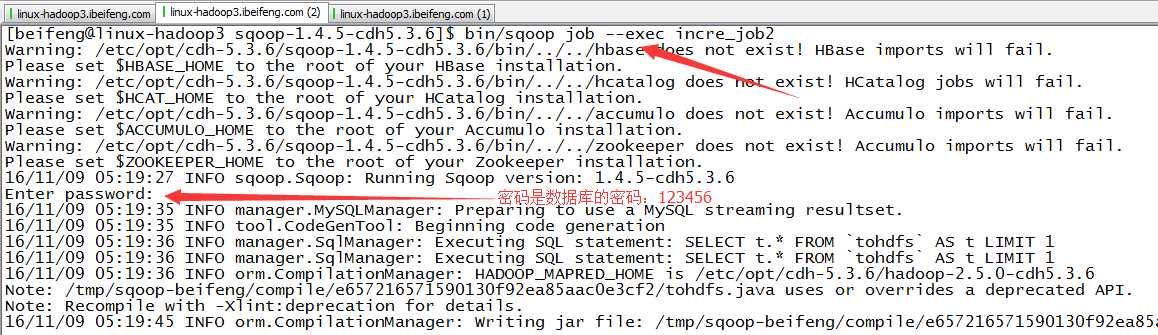
17.执行job任务
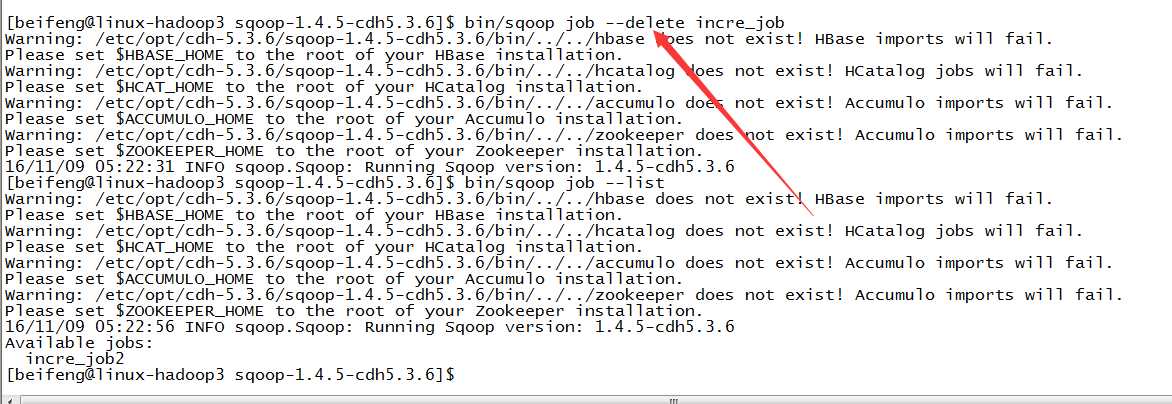
18.删除job任务
二:导入 mysql-->hive
1.在HIVE中新建一个数据库和一个表
方便mysql里面的数据导入。

2.展示源表tohdfs的数据
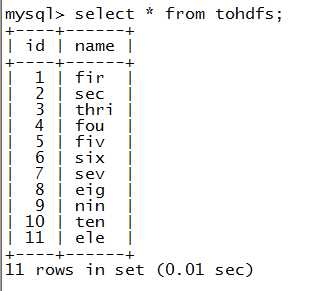
3.导入一
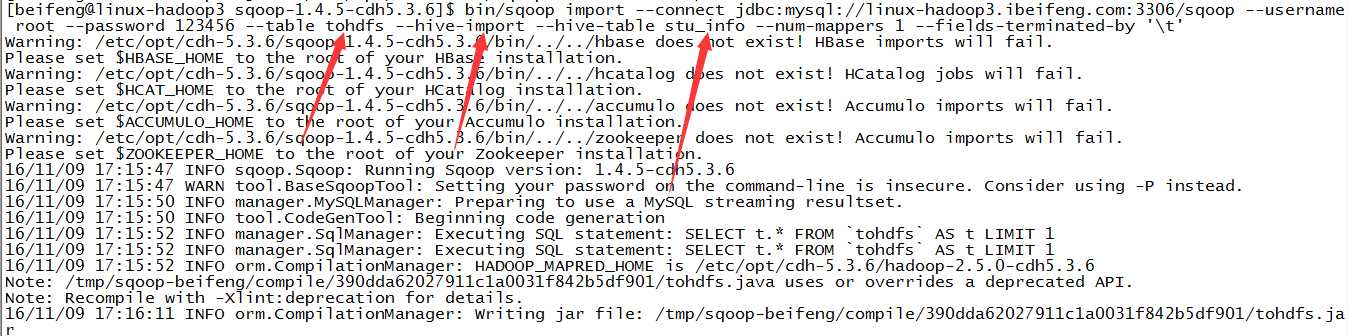
4.结果

5.导入二
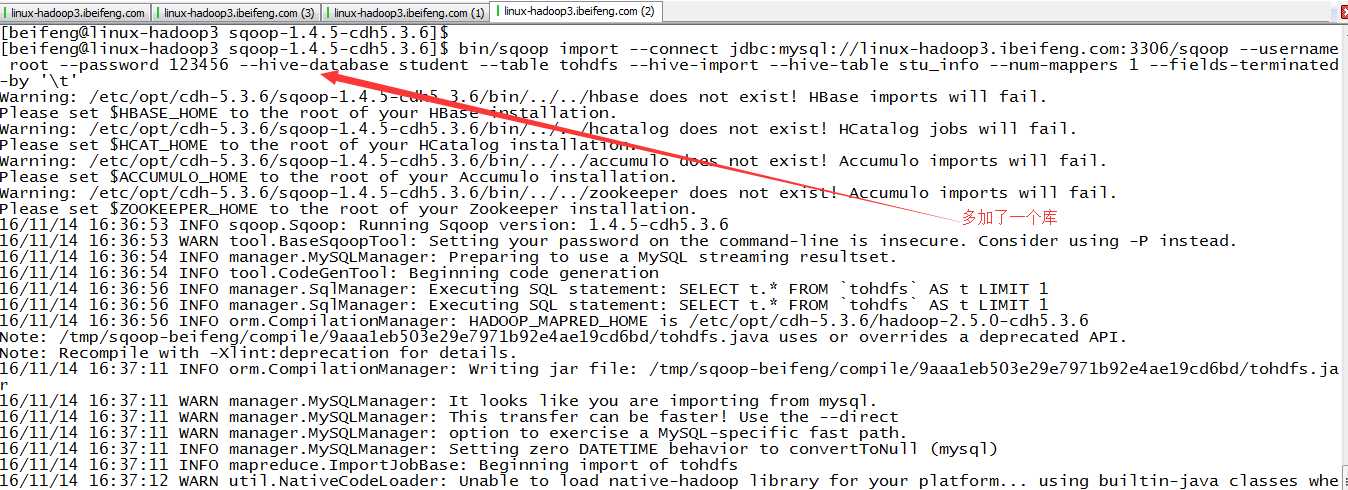
6.结果

三:导出:hdfs-》mysql
1.新建mysql数据表
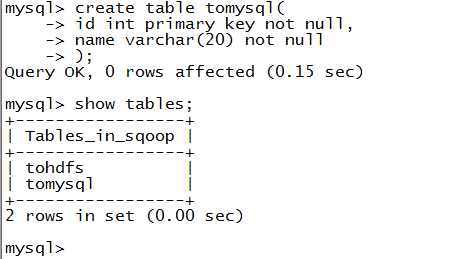
2.命令
bin/sqoop export --connect jdbc:mysql://linux-hadoop3.ibeifeng.com:3306/sqoop --username root --password 123456 --table tomysql --export-dir /user/hive/warehouse/student.db/stu_info --num-mappers 1 --input-fields-terminated-by ‘\t‘
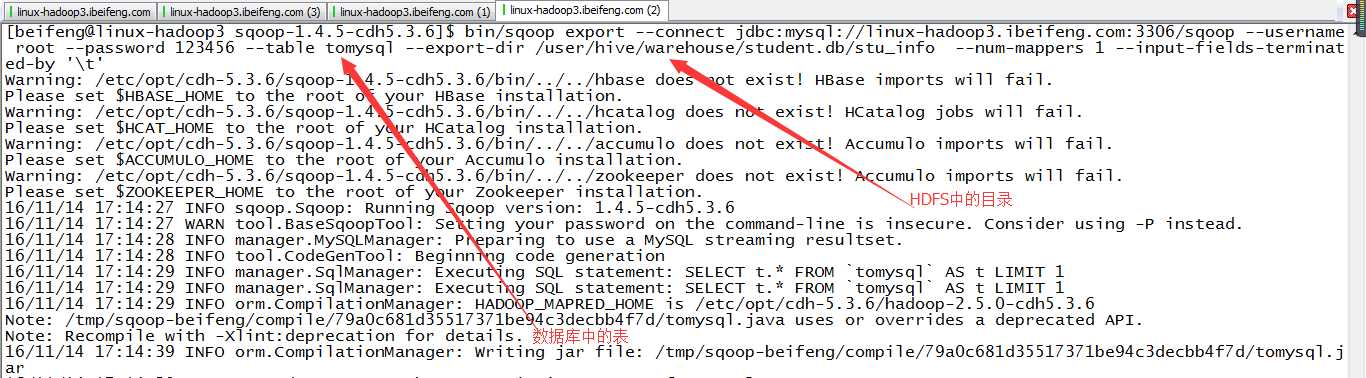
3.结果
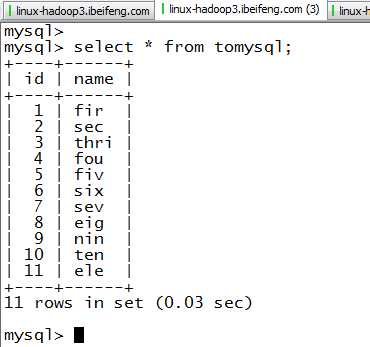
四:导出hive-》mysql
1.基本语法同上。
只需要把--export-dir改成HIVE的路径就可以了。
但是会发现,上面的HDFS上的路径就是HIVE的路径,所以HIVE的导出例子依旧可以使用上面的例子。
在HDFS的导出中,可以使用HDFS上的任何一个路径,而不是HIVE中需要时warehouse的路径。
五:执行sqoolwenjian
1.新建数据库
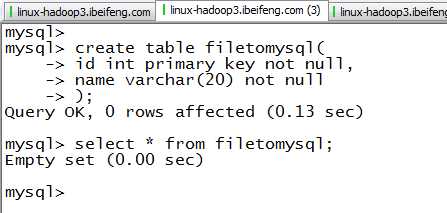
2.新建sqoop.file,里面是将执行的文件
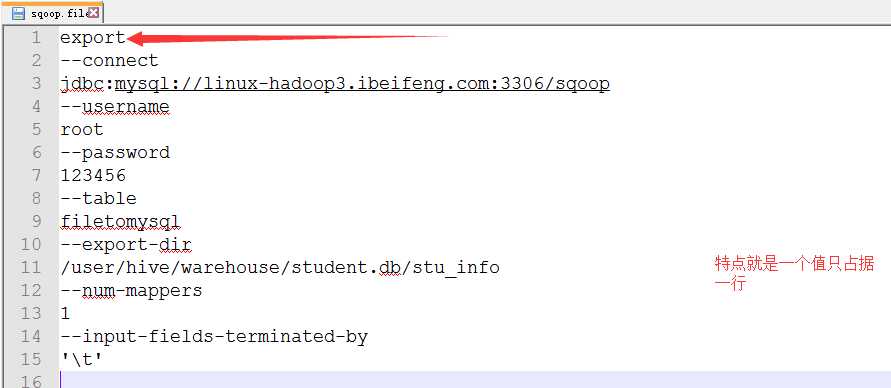
3.执行
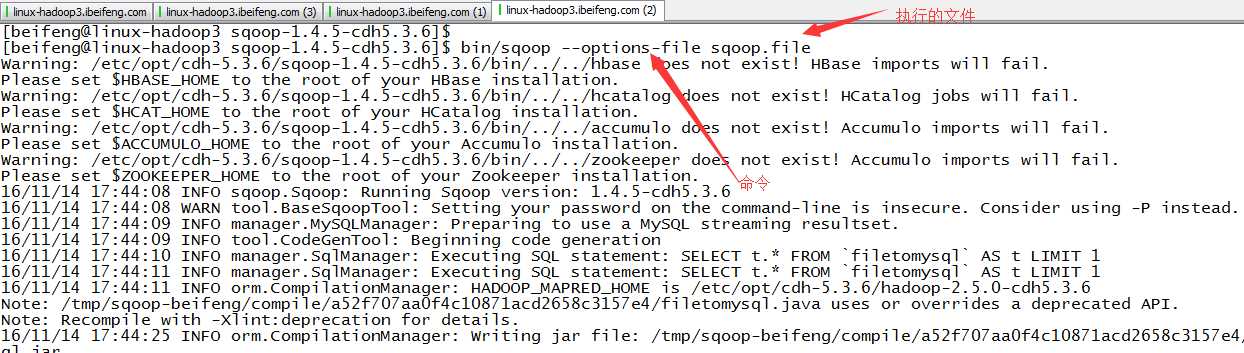
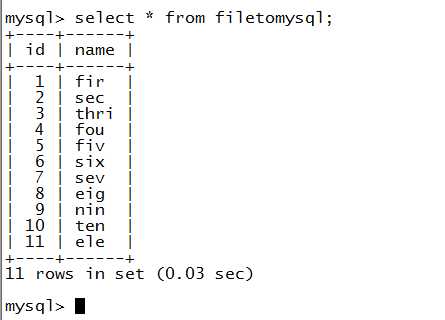
4.结果
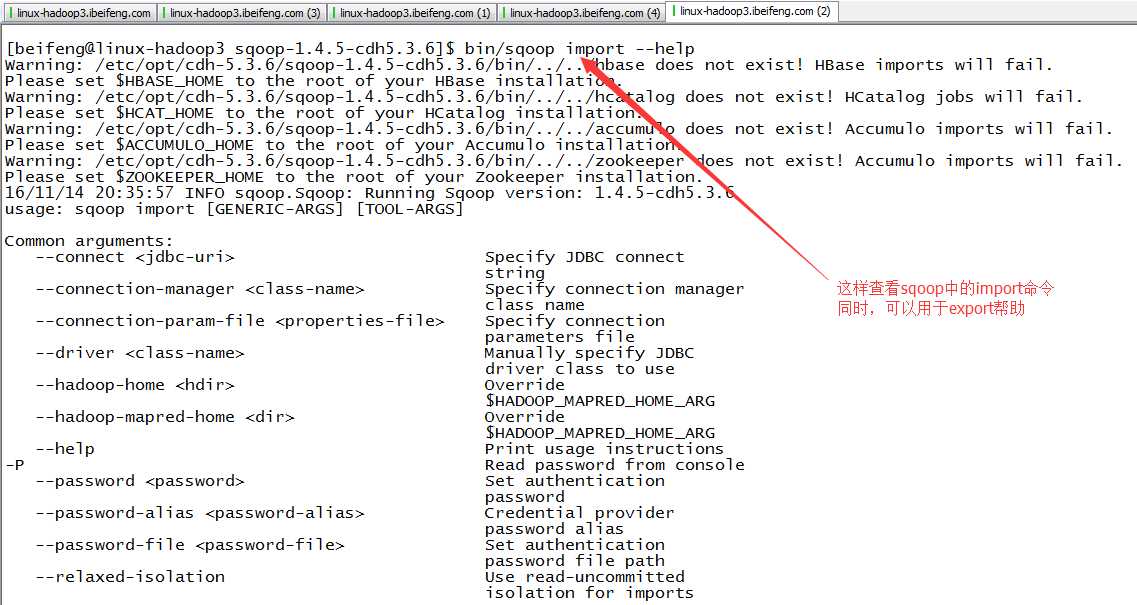
六:使用帮助
1.用法
原文:http://www.cnblogs.com/RHadoop-Hive/p/7414025.html