首先实现rdd缓存
准备了500M的数据 10份,每份 100万条,存在hdfs 中通过sc.textFile方法读取
val rdd1 = sc.textFile("hdfs://mini1:9000/spark/input/visitlog").cache
在启动spark集群模式时分配内存2g,第一次分配1g 只缓存了40%
然后调用cache方法
rdd1.count
第二次调用rdd的count方法就显示出差距了
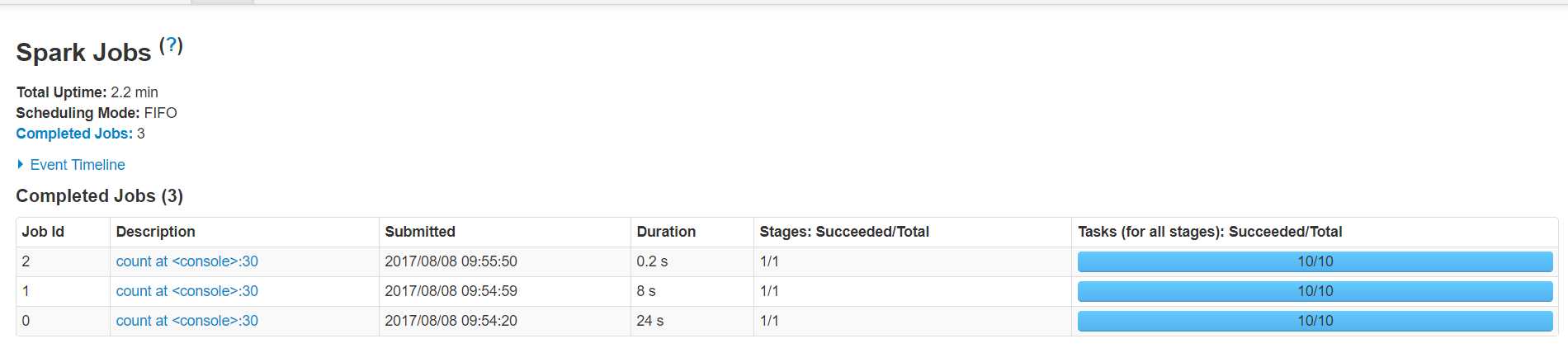
原文:http://www.cnblogs.com/rocky-AGE-24/p/7305708.html