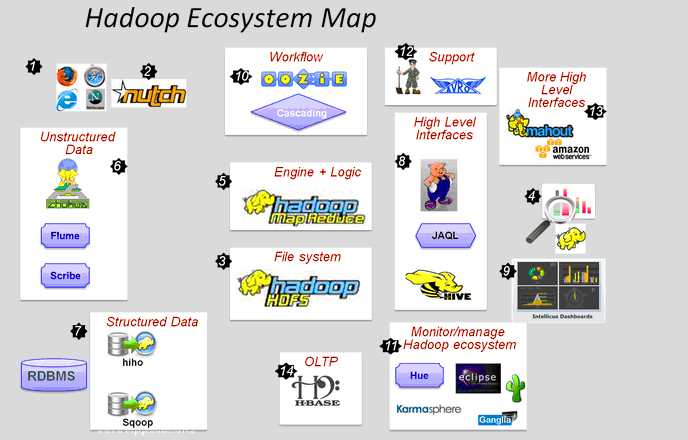
- How did it all start- huge data on the web!
- Nutch built to crawl this web data
- Huge data had to saved- HDFS was born!
- How to use this data?
- Map reduce framework built for coding and running analytics – java, any language-streaming/pipes
- How to get in unstructured data – Web logs, Click streams, Apache logs, Server logs – fuse,webdav, chukwa, flume, Scribe
- Hiho and sqoop for loading data into HDFS – RDBMS can join the Hadoop band wagon!
- High level interfaces required over low level map reduce programming– Pig, Hive, Jaql
- BI tools with advanced UI reporting- drilldown etc- Intellicus
- Workflow tools over Map-Reduce processes and High level languages
- Monitor and manage hadoop, run jobs/hive, view HDFS – high level view- Hue, karmasphere, eclipse plugin, cacti, ganglia
- Support frameworks- Avro (Serialization), Zookeeper (Coordination)
- More High level interfaces/uses- Mahout, Elastic map Reduce
- OLTP- also possible – Hbase
Hadoop ecosystem,布布扣,bubuko.com
Hadoop ecosystem
原文:http://www.cnblogs.com/AloneSword/p/3789835.html