很简单的实践,
其他没有特别需要注意的,实现如下:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ[‘TF_CPP_MIN_LOG_LEVEL‘] = ‘2‘
learning_rate = 0.01 # 学习率
training_epochs = 20 # 训练轮数,1轮等于n_samples/batch_size
batch_size = 128 # batch容量
display_step = 1 # 展示间隔
example_to_show = 10 # 展示图像数目
n_hidden_units = 256
n_input_units = 784
n_output_units = n_input_units
def WeightsVariable(n_in, n_out, name_str):
return tf.Variable(tf.random_normal([n_in, n_out]), dtype=tf.float32, name=name_str)
def biasesVariable(n_out, name_str):
return tf.Variable(tf.random_normal([n_out]), dtype=tf.float32, name=name_str)
def encoder(x_origin, activate_func=tf.nn.sigmoid):
with tf.name_scope(‘Layer‘):
Weights = WeightsVariable(n_input_units, n_hidden_units, ‘Weights‘)
biases = biasesVariable(n_hidden_units, ‘biases‘)
x_code = activate_func(tf.add(tf.matmul(x_origin, Weights), biases))
return x_code
def decode(x_code, activate_func=tf.nn.sigmoid):
with tf.name_scope(‘Layer‘):
Weights = WeightsVariable(n_hidden_units, n_output_units, ‘Weights‘)
biases = biasesVariable(n_output_units, ‘biases‘)
x_decode = activate_func(tf.add(tf.matmul(x_code, Weights), biases))
return x_decode
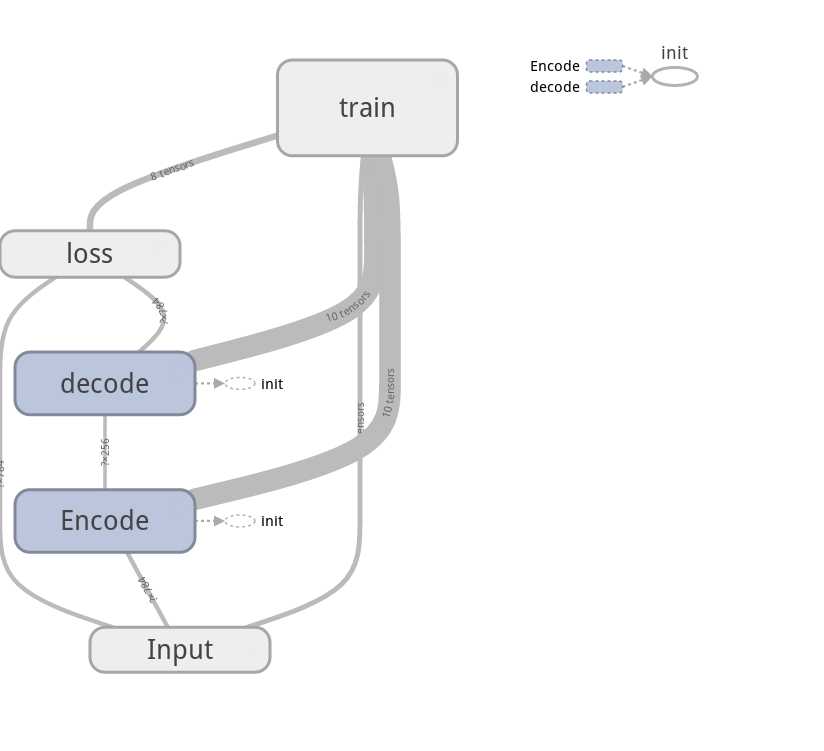
with tf.Graph().as_default():
with tf.name_scope(‘Input‘):
X_input = tf.placeholder(tf.float32, [None, n_input_units])
with tf.name_scope(‘Encode‘):
X_code = encoder(X_input)
with tf.name_scope(‘decode‘):
X_decode = decode(X_code)
with tf.name_scope(‘loss‘):
loss = tf.reduce_mean(tf.pow(X_input - X_decode, 2))
with tf.name_scope(‘train‘):
Optimizer = tf.train.RMSPropOptimizer(learning_rate)
train = Optimizer.minimize(loss)
init = tf.global_variables_initializer()
# 因为使用了tf.Graph.as_default()上下文环境
# 所以下面的记录必须放在上下文里面,否则记录下来的图是空的(get不到上面的default)
writer = tf.summary.FileWriter(logdir=‘logs‘, graph=tf.get_default_graph())
writer.flush()
计算图:
原文:http://www.cnblogs.com/hellcat/p/6977830.html