本实例主要通过抓取慕课网的课程信息来展示scrapy框架抓取数据的过程。
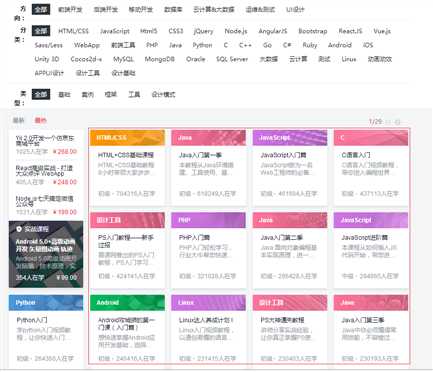
抓取网站:http://www.imooc.com/course/list
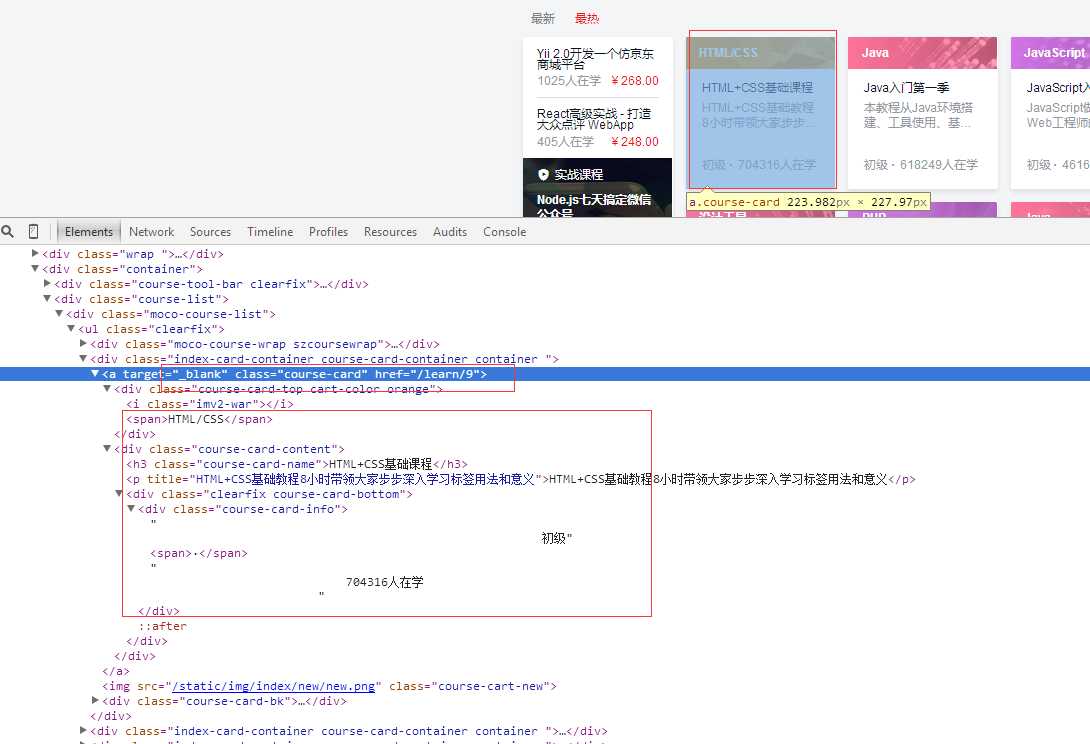
抓取内容:要抓取的内容是全部的课程名称,课程简介,课程URL ,课程图片URL,课程人数(由于动态渲染暂时没有获取到)
网站图片:
在命令行模式建立工程
scrapy startproject scrapy_course
建立完成后,用pycharm打开,目录如下:
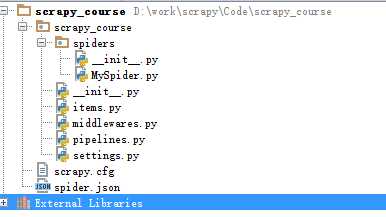
scrapy.cfg: 项目的配置文件
scrapytest/: 该项目的python模块。之后您将在此加入代码。
scrapytest/items.py: 项目中的item文件.
scrapytest/pipelines.py: 项目中的pipelines文件.
scrapytest/settings.py: 项目的设置文件.
scrapytest/spiders/: 放置spider代码的目录.
下面按步骤讲解如何编写一个简单的爬虫。
我们要编写爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
文件包含一个MySpider类,它必须继承scrapy.Spider类。
同时它必须定义一下三个属性:
-name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
-start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
-parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
原文:http://www.cnblogs.com/shaosks/p/6909379.html