
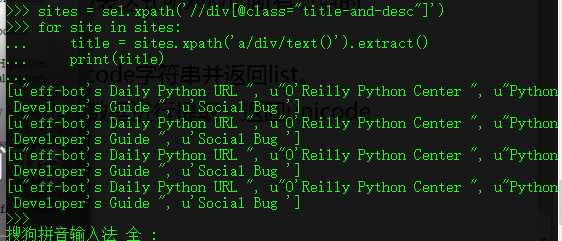
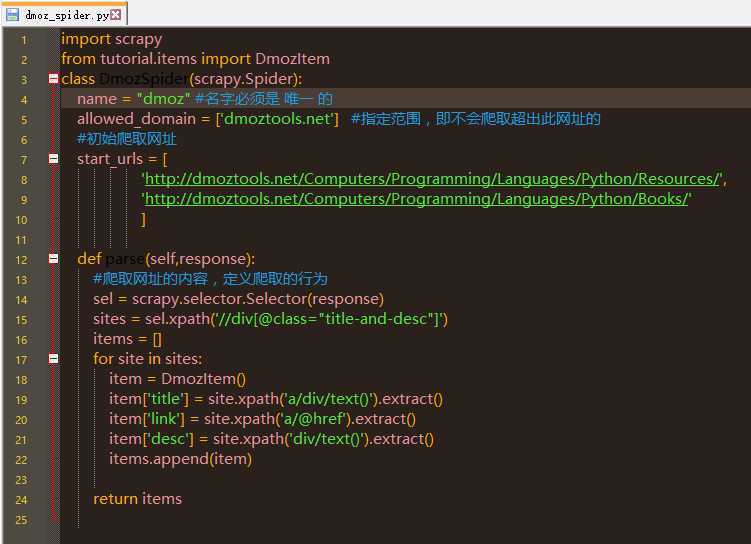
# -*- coding: utf-8 -*-# Define here the models for your scraped items## See documentation in:# http://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass DmozItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()link = scrapy.Field()desc = scrapy.Field()

原文:http://www.cnblogs.com/tcheng/p/6888939.html