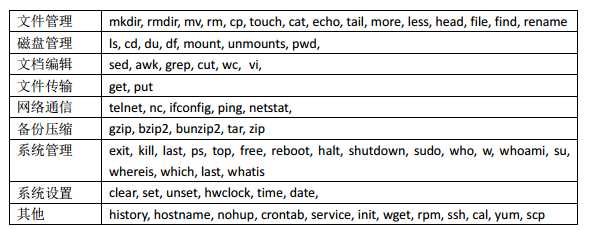
一、常用命令归纳分类
课外网站 http://man.linuxde.net/
http://www.jb51.net/linux/
https://jaywcjlove.github.io/linux-command/
如果想查看命令的使用手册可以使用 man, 例如man clear
二、常用命令详解
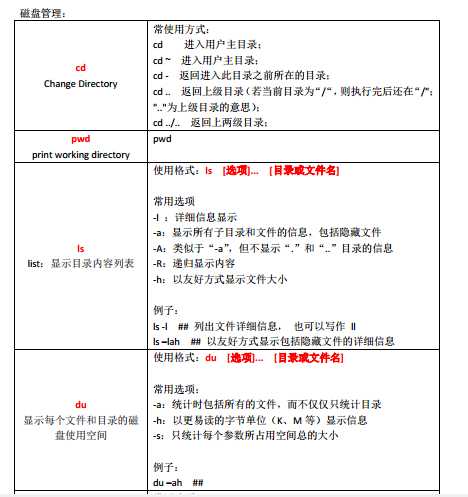
1、磁盘管理

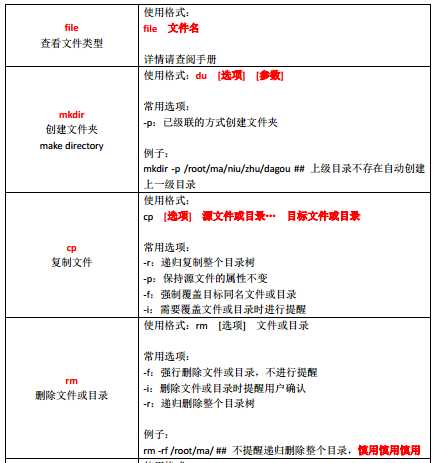
2、文件管理

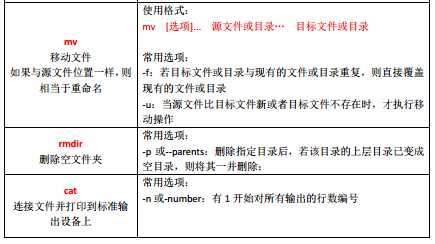
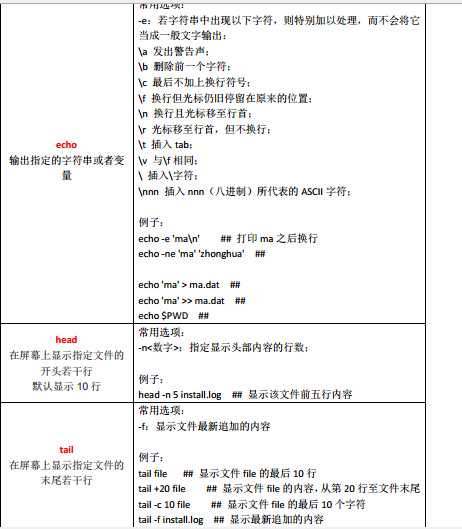
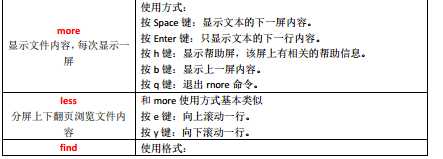
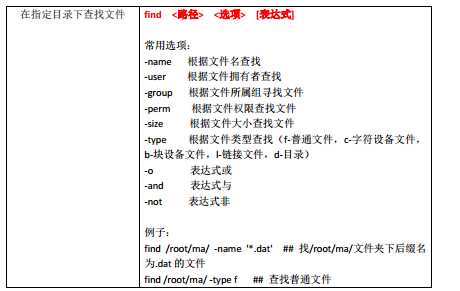
其他命令:

三、vi 文本编辑器
VI,是 linux 操作系统中最常用的文本编辑器, VIM 是它的增强版本, VI 有三种基本工作模式,分别是:命令模式 ( command mode)、插入模式 ( insert mode)和底行模式 ( last line mode)
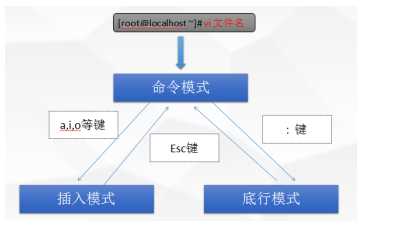
1、最基本用法
vi huangbo.txt
(1)首先会进入“一般模式”,此模式只接受各种命令快捷键,不能编辑文件内容
(2)按 i 键,就会从一般模式进入编辑模式,此模式下,敲入的都是文件内容
(3)编辑完成之后,按 Esc 键退出编辑模式,回到一般模式;
(4)再按:,进入“底行命令模式”,输入 wq 命令,回车即可保存退出
移动光标:使用上下左右键移动光标 也可以使用hjkl,依次是向前下上右移动
2、常用快捷键

3、查找并替换(在底行命令模式中输入)

4、替换操作

补充:VIM 详解: http://linux.ctolib.com/cheat-sheets/view/Vim-command.html
四、压缩打包
1、gzip 压缩 : gzip ma.txt
2、gzip解压缩 : gzip -d ma.txt.gz
3、bzip2 压缩 : bzip2 ma.dat
4、bzip2 解压缩 bzip2 -d ma.dat.bz2 或者 bunzip2 ma.dat.bz2
5、打包 tar -cvf ma.txt.tar ma.txt (ma.txt.tar是打包生成的包名)
追加打包 tar -rvf ma.txt.tar ma.dat 表示将 ma.dat 文件追加到 ma.txt.tar 当中
6、解包 tar -xvf ma.txt.tar
7、打包并压缩 tar -zcvf ma.tar.gz /root/ma/
8、解包并解压缩 tar -zxvf ma.tar.gz
tar -zxvf ma.tar.gz -C /home/hadoop/liuwei 解压到指定目录
9、查看压缩包内容 tar -ztvf ma.tar.gz
10、打包并压缩成bz2 tar -jcvf a.tar.bz2
11、解压bz2 tar -jxvf a.tar.bz2
相关参数的解释:
五、用户和组
1、组操作
添加一个叫 bigdata 的组 groupadd bigdata
查看系统当前有那些组 cat /etc/group
将 hadoop 添加到 bigdata 组中 usermod -g bigdata spark 或者 gpasswd -a spark bigdata
将 spark 用户从 bigdata 组删除 gpasswd -d spark bigdata
将 bigdata 组名修改为 bigspark groupmod -n bigspark bigdata
删除组 groupdel bigdata
2、用户操作
添加用户
useradd spark
usermod -g bigdata spark 设置组
usermod -c "mylove spark" spark 添加备注信息
一步完成 useradd -g bigdata -c "mylove" spark
设置密码
password spark
修改用户
修改spark登录名 usermod -l spark storm
将spark 添加到bigdata 和root组 usermod -G root,bigdata spark
查看spark的组信息 groups spark
删除用户 userdel -r spark 加一个-r 代表把用户和用户的主目录都删除
3、为用户配置 sudoer 权限
用 root 编辑 vi /etc/sudoers
在文件的如下位置,为 hadoop 添加一行即可
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
spark ALL=(ALL) ALL
然后, hadoop 用户就可以用 sudo 来执行系统级别的指令
六、文件权限
1、Linux文件权限解读
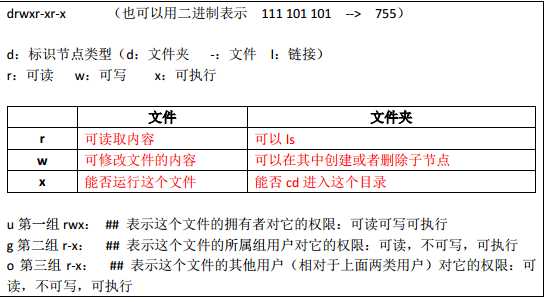
2、修改文件权限
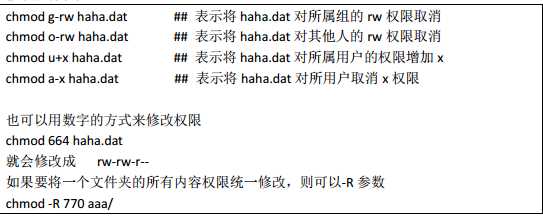
3、修改文件所有权

七、修改系统时间
原文:http://www.cnblogs.com/liuwei6/p/6663645.html