一、堆栈的概念
一种含有插入(push)和弹出(pop)操作的ADT,而且在该数据结构中,弹出符合先进后出的规则,插入则是直接将数据置于该ADT的顶层。看个简单的丑图吧
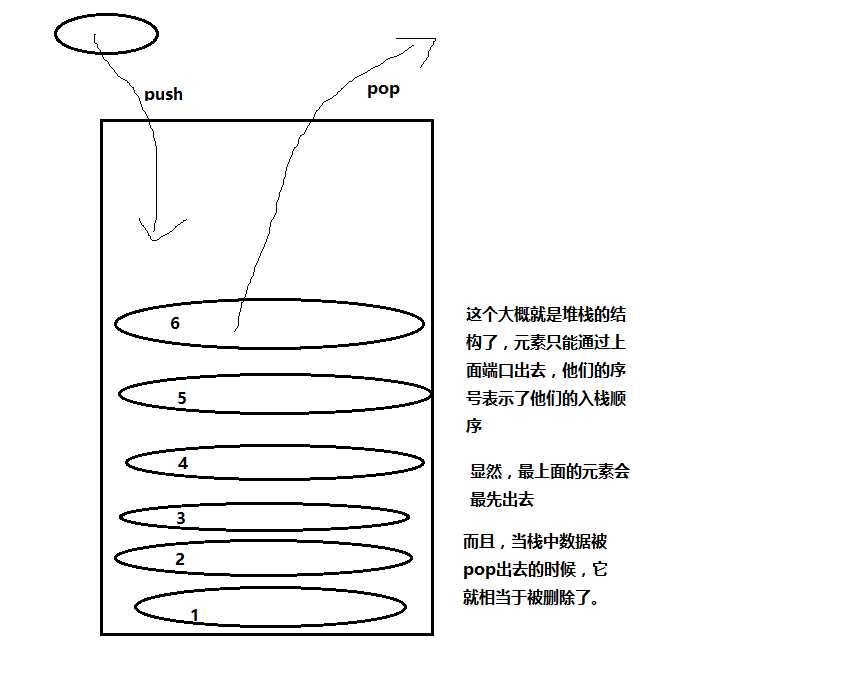
恩,具体的结构解释上图说得挺清楚的了,图是有点丑,各位凑合看下。
二、堆栈的实现方式
1、pop方法实现方式(基于链表)
一般来说,堆栈的实现方式是通过链表来实现的,每次pop将链表的最后一个指针返回,修改顶端的元素并调用链表的delete操作即可;具体代码如下:
//弹出
public LinkSingleIntNode pop() throws RuntimeException{
if(size==0){
throw new RuntimeException( "无元素");
}
LinkSingleIntNode rtn = point;
link.deleteNode(point);
point = link.linkTail;//栈顶改变为上一个元素
size--;
return rtn;
}
2、push方法的实现方式(基于链表)
同样,push的实现方式其实就是链表的add操作,然后将栈顶改为新增的元素即可;具体代码如下:
//入栈
public boolean push(LinkSingleIntNode node){
boolean rtn = false;
link.addNode(node);
point = node;
size++;
rtn = true;
return rtn;
}
完整的栈代码也比较简单,只要实现了链表,栈的实现就很简单啦:
public class HeapInt {
/*
*
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
HeapInt heap = new HeapInt();
heap.push(new LinkSingleIntNode(1));
int num = heap.pop().data;
System.out.println(num);
//int num1 = heap.pop().data;
//System.out.println(num1);
heap.push(new LinkSingleIntNode(111));
heap.push(new LinkSingleIntNode(122));
//
ArrayList<Integer> list = heap.link.findAll();
System.out.println(heap.pop().data);
ArrayList<Integer> list1 = heap.link.findAll();
System.out.println(heap.pop().data);
heap.push(new LinkSingleIntNode(105));
heap.push(new LinkSingleIntNode(107));
System.out.println(heap.pop().data);
} catch (Exception e) {
// TODO: handle exception
System.out.println("已到栈底");
}
}
public LinkSingleIntNode point = null;//栈顶
private LinkSingleInt link = null;//栈的实现链表
public int size = 0;//栈元素个数
public HeapInt(){
point = new LinkSingleIntNode();
link = new LinkSingleInt();
}
//入栈
public boolean push(LinkSingleIntNode node){
boolean rtn = false;
link.addNode(node);
point = node;
size++;
rtn = true;
return rtn;
}
//弹出
public LinkSingleIntNode pop() throws RuntimeException{
if(size==0){
throw new RuntimeException( "无元素");
}
LinkSingleIntNode rtn = point;
link.deleteNode(point);
point = link.linkTail;//栈顶改变为上一个元素
size--;
return rtn;
}
}
三、栈的具体用途
可能你会说,栈好像看起来并没有什么卵用啊,干嘛要这种数据结构啊?其实,栈在计算机里面的用处大着呢,因为它本身就是体现一种计算机执行程序的基本步骤:从某个点断开(中断)相应更高级别的请求-->将断点状态压入栈-->响应请求-->重复上一个步骤-->...;计算机的运行很多时候就是那个循环,栈保证了程序执行两个必要信息:一个是状态信息本身,一个是状态信息恢复的顺序(先入栈的后恢复).
当然,栈还有很多其他妙用,具体请查看我的下一篇博客-->栈与四则运算
原文:http://www.cnblogs.com/lcplcpjava/p/6576438.html