一开始用了实验楼的环境,发现第一次编译几乎要用半小时,之后增量编译的速度倒是挺快。可是一旦实验时间用完没有点“延时”,实验楼环境就被回收,又要重新编译(╯‵□′)╯︵┻━┻。实验楼的会员价值原来在这里。
于是决定改用自己的虚拟机一劳永逸。而且直接用32位版本,也省得每次编译都-m32。
装好虚拟机以及ubuntu以后,按照mykernel的指示,安装了qemu,下载了3.9.4的kernel代码以及mykernel的代码。
解压缩以后用 patch -p1 < ../mykernel_for_linux3.9.4sc.patch打上补丁,然后 make allnoconfig ,最后 make 开始编译
结果编译一开始就提示
fatal error: linux/compiler-gcc5.h: No such file or directory
在网上查了一下,应该是因为我的Ubuntu16.04版本较高。于是下载一份最新的compiler-gcc.h,然后重名名为compiler-gcc5.h,并复制到include/linux目录下,再次编译就顺利完成了。此时深感实验楼环境之低端,我的虚拟机只需要1分钟就完成初次编译。
接下来从mykernel下载myinterrupt.c,mymain.c以及mypcb.h三个文件,放在mykernel目录中,居然编译失败(⊙?⊙)
仔细一看,mypcb.h里面赫然写着 #define KERNEL_STACK_SIZE 1024*2 # unsigned long ,怎么会出这种低级错误。一看代码提交时间,居然是2017年3月,看来是这几天匆匆修改的。
顺便看了一下另外两个文件的修改,原来是把代码进行了简化,功能不变。于是修改掉这里的错误,再次编译内核,然后启动qemu载入内核运行
qemu -kernel arch/x86/boot/bzImage
刷新太快了!!!将mymain.c的64行
if(i%10000000 == 0)
增加30倍,改为
if(i%300000000 == 0)
刷新的速度终于可以接受了。
可以看到qemu的窗口中不断打印当前进程ID
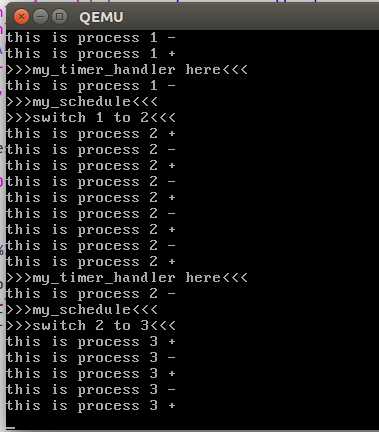
下面开始分析这三个文件。
首先是最简单的头文件mypcb.h
主要定义了两个结构体
struct Thread { unsigned long ip; unsigned long sp; };
以及
typedef struct PCB{ int pid; volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ unsigned long stack[KERNEL_STACK_SIZE]; /* CPU-specific state of this task */ struct Thread thread; unsigned long task_entry; struct PCB *next; }tPCB;
其中Thread用于保存进程的EIP与ESP寄存器,当再次轮转到该进程时,可以恢复先前的状态,继续运行。
而PCB用于保存了进程的信息,包括进程ID、调度状态、堆栈空间、寄存器、入口地址,以及指向下一个进程PCB的指针,从而构成进程调度链表。
接下来看mymain.c。首先看内核的入口函数my_start_kernel
1 void __init my_start_kernel(void) 2 { 3 int pid = 0; 4 int i; 5 /* Initialize process 0*/ 6 task[pid].pid = pid; //填写0号进程ID 7 task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */ //设置进程为可运行状态 8 task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process; //设置进程的入口函数为my_process,将其IP也指向这里,从这个函数开始运行 9 task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1]; //将0号进程的SP指向堆栈的栈底,表示当前堆栈为空 10 task[pid].next = &task[pid]; //下一个PCB指针指向自身,构成循环链表 11 /*fork more process */ 12 for(i=1;i<MAX_TASK_NUM;i++) 13 { 14 memcpy(&task[i],&task[0],sizeof(tPCB)); //复制0号进程的信息 15 task[i].pid = i; //进程ID修改为i号 16 task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1]; //SP指向各自堆栈的栈底,表示堆栈为空 17 *((unsigned long*)task[i].thread.sp - 1) = task[i].thread.sp; //将BP压入栈中 18 task[i].thread.sp -= 1; 19 task[i].next = task[i-1].next; //将当前进程的PCB插入调度链表 20 task[i-1].next = &task[i]; 21 } 22 /* start process 0 by task[0] */ 23 pid = 0; 24 my_current_task = &task[pid]; 25 asm volatile( 26 "movl %1,%%esp\n\t" /* set task[pid].thread.sp to esp */ 27 "pushl %1\n\t" /* push ebp */ 28 "pushl %0\n\t" /* push task[pid].thread.ip */ 29 "ret\n\t" /* pop task[pid].thread.ip to eip */ 30 "popl %%ebp\n\t" 31 : 32 : "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/ 33 ); 34 }
该函数先是创建了0号进程,6-10行填写了0号进程的PCB表。
12-21行的循环用于创建其余进程。所有进程都处于最初状态,IP指向入口地址,SP指向各自栈底。其中17-18行将BP压入栈中是最近更新的,这个压栈使得后面的调度简化,不用再区分是否初次运行进程,可惜引入了新的bug。
然后从0号进程开始运行,将当前进程指针指向0号进程的PCB
26行将0号进程的thread.sp变量写入ESP寄存器。
因为thread.sp变量此时也指向栈底,所以27行实际上将0号进程的BP压栈。然而这行代码并没有什么用,因为根据后面的分析,这里压栈的bp不会被使用。所以是个bug
因为EIP寄存器无法直接写入,因此28-29行通过先压栈再ret的方法,间接的把thread.ip的值写入EIP寄存器。
30行其实是不会运行的,因为29行已经将EIP指向了0号进程的入口地址,即my_process函数。
内核启动完成。接下来开始由各个进程轮转运行。最开始是0号进程开始运行my_process函数。
1 void my_process(void) 2 { 3 int i = 0; 4 while(1) 5 { 6 i++; 7 if(i%300000000 == 0) 8 { 9 printk(KERN_NOTICE "this is process %d -\n",my_current_task->pid); 10 if(my_need_sched == 1) 11 { 12 my_need_sched = 0; 13 my_schedule(); 14 } 15 printk(KERN_NOTICE "this is process %d +\n",my_current_task->pid); 16 } 17 } 18 }
每300000000次循环输出一次 this is process i - 。然后看是否需要调度下一个进程,如果不需要调度,就输出 this is process i + ;否则进行调度。
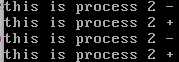
上图就是无需调度的运行情形
调度的标志是在时钟中断里面设置的,所以最后看myinterrupt.c的时钟中断。
1 void my_timer_handler(void) 2 { 3 #if 1 4 if(time_count%1000 == 0 && my_need_sched != 1) 5 { 6 printk(KERN_NOTICE ">>>my_timer_handler here<<<\n"); 7 my_need_sched = 1; 8 } 9 time_count ++ ; 10 #endif 11 return; 12 }
这里每1000次中断,就打印一行 >>>my_timer_handler here<<< ,并且设置调度标志。当my_process下次判断调度标志的时候,就会调用调度函数my_schedule
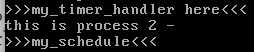
上图就是先产生了调度请求,然后my_process经过判断以后进入调度分支
1 void my_schedule(void) 2 { 3 tPCB * next; 4 tPCB * prev; 5 6 if(my_current_task == NULL 7 || my_current_task->next == NULL) 8 { 9 return; 10 } 11 printk(KERN_NOTICE ">>>my_schedule<<<\n"); 12 /* schedule */ 13 next = my_current_task->next; 14 prev = my_current_task; 15 if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */ 16 { 17 my_current_task = next; 18 printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid); 19 /* switch to next process */ 20 asm volatile( 21 "pushl %%ebp\n\t" /* save ebp */ 22 "movl %%esp,%0\n\t" /* save esp */ 23 "movl %2,%%esp\n\t" /* restore esp */ 24 "movl $1f,%1\n\t" /* save eip */ 25 "pushl %3\n\t" 26 "ret\n\t" /* restore eip */ 27 "1:\t" /* next process start here */ 28 "popl %%ebp\n\t" 29 : "=m" (prev->thread.sp),"=m" (prev->thread.ip) 30 : "m" (next->thread.sp),"m" (next->thread.ip) 31 ); 32 } 33 return; 34 }
调度函数首先确保当前进程以及下一个进程的PCB都是有效的,然后输出 >>>my_schedule<<< 表示进入调度程序。
15行判断下一个进程是否处于可调度状态。这里新代码和老代码不同,所有的进程都是可调度状态,不需要else分支初始化一个进程。
20-30行的内联汇编代码是操作系统两把宝剑之一——进程上下文切换的关键点。
21行将当前进程的EBP寄存器压栈保存,22行将ESP寄存器保存在thread.sp变量中。
24行将下次恢复运行时的地址保存在thread.ip变量中,这个地址的第一条指令是28行的popl %ebp,即将21行压栈的EBP恢复。
23行从下一个进程的thread.sp变量中恢复了下一个进程的ESP寄存器
25、26行从下一个进程的thread.ip变量中恢复了下一个进程的EIP寄存器。
这里分两种情况:
根据my_start_kernel中的进程初始化代码,EIP是指向my_process函数的,即从头运行my_process。然而这里依然有bug,新进程的EBP寄存器并未设置。而且我们可以得知,所有进程其实用的都是内核my_start_kernel的EBP
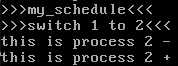
可以看出进程2先输出了2-。
根据my_schedule中24行的汇编代码,EIP是指向28行的popl %ebp,即将之前压栈的EBP恢复。然后运行return语句,返回my_process函数恢复先前的运行。
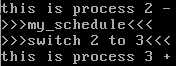
可以看到,调度之前输出2-,运行调度函数以后输出3+。即已经切换到了进程3,而且是从my_schedule后面继续运行。
而下次再调度进程2的情形是
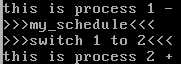
如果只关注进程2,则进程2先输出2-,后输出2+,是连续运行的。即调度对于进程是透明的。
总结
操作系统的进程调度模块就是不断查找满足调度条件的进程,然后将当前进程的现场保存起来,再恢复下一个调度进程的运行现场。对于进程来说,调度过程是透明的。
最后再证明一下新代码的bug。
这个是my_start_kernel的ESP和EBP
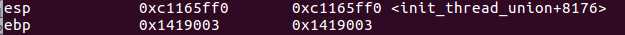
这个是进程1的ESP和EBP

这个是进程2的ESP和EBP

可以看出ESP确实切换了,EBP却始终不变。
王岩
原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
原文:http://www.cnblogs.com/cscat/p/6504582.html