2017年3月1日, 星期三
下载地址:http://spark.apache.org/downloads.html
Standalone模式的spark集群虽然不依赖于yarn,但是数据文件存在hdfs,所以需要hdfs集群启动成功
这里下载包也要根据hadoop集群版本启动
比如hadoop2.5.2需要下载spark-1.4.0-bin-hadoop2.4.tgz
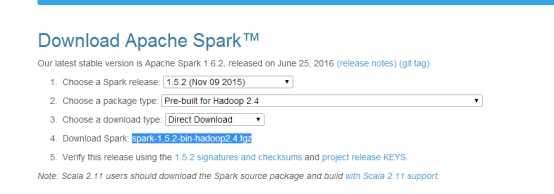
下载解压进入解压缩目录

配置spark-env.shexport SPARK_MASTER_IP=masterexport SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=1export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=1G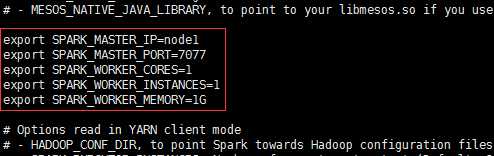
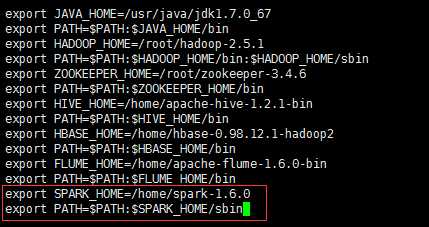


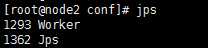
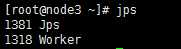



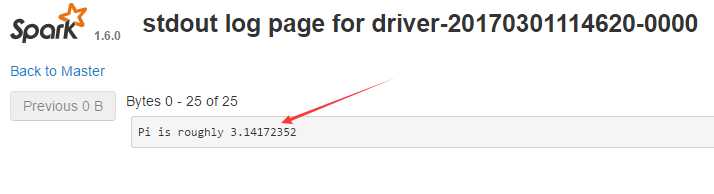
访问node1:8080能看到Spark web界面
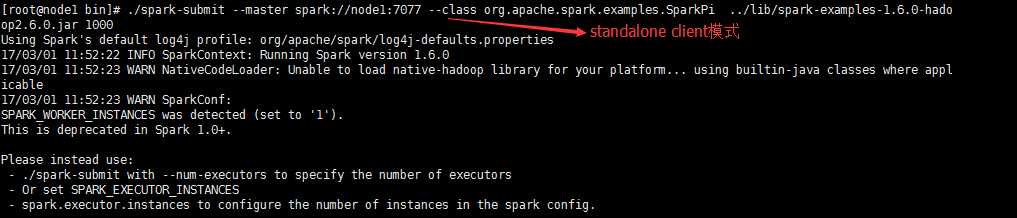
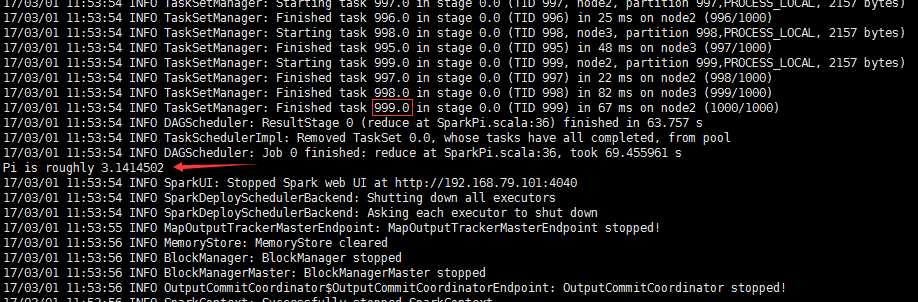
不同运行模式的命令不同1.standalone client模式./bin/spark-submit --class org.apache.spark.examples.SparkPi--master spark://master:7077 --executor-memory 512m --total-executor-cores 1 ./lib/spark-examples-1.5.2-hadoop2.4.0.jar 1002.standalone cluster模式./bin/spark-submit --class org.apache.spark.examples.SparkPi--master spark://spark001:7077 --driver-memory 512m --deploy-mode cluster --supervise --executor-memory 512M --total-executor-cores 1 ./lib/spark-examples-1.5.2-hadoop2.4.0.jar 1003.on yarn client模式./bin/spark-submit --class org.apache.spark.examples.SparkPi--master yarn-client --executor-memory 512M--num-executors 1./lib/spark-examples-1.5.2-hadoop2.4.0.jar 1004.on yarn cluster模式./bin/spark-submit --class org.apache.spark.examples.SparkPi--master yarn-cluster --executor-memory 512m--num-executors 1./lib/spark-examples-1.5.2-hadoop2.4.0.jar 100SparkSQL与Hive整合1、只需要在master节点的conf里面创建一个hive-site.xml 然后里面的配置是:<configuration><property><name>hive.metastore.uris</name><value>thrift://hadoop1:9083</value><description>Thrift uri for the remote metastore.Used by metastore client to connect to remote metastore.</description></property></configuration>2、启动hive的metastore服务
原文:http://www.cnblogs.com/haozhengfei/p/f421e517457b01f6db36d934bfab5ac6.html