项目开始用的是spark core操作rdd进行大数据计算,后来经过高人点拨使用spark sql,发现spark sql确实好用很多,留下一些笔记。。
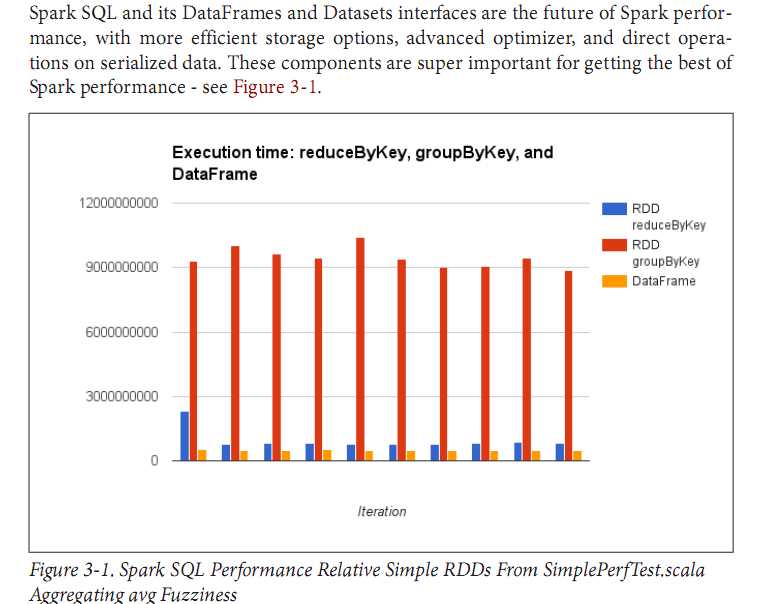
在OReilly即将推出的力作《High Performance Spark》中有这样一段文字,我想看了后也能增加使用spark sql的决心。
关于spark sql的概念不想多讲,有兴趣的朋友可以参考各种网上的资料,直接开始吧
可以通过如下数据源创建DataFrame:
1.已有的RDD
通过定义Case Class,使用反射推断Schema(case class方式)
// sc is an existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // this is used to implicitly convert an RDD to a DataFrame. import sqlContext.implicits._ // Define the schema using a case class. // Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit, // you can use custom classes that implement the Product interface. case class Person(name: String, age: Int) // Create an RDD of Person objects and register it as a table. val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF() people.registerTempTable("people") // SQL statements can be run by using the sql methods provided by sqlContext. val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
通过可编程接口,定义Schema,并应用到RDD上(applySchema 方式)
// sc is an existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // Create an RDD val people = sc.textFile("examples/src/main/resources/people.txt") // The schema is encoded in a string val schemaString = "name age" // Import Row. import org.apache.spark.sql.Row; // Import Spark SQL data types import org.apache.spark.sql.types.{StructType,StructField,StringType}; // Generate the schema based on the string of schema val schema = StructType( schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true))) // Convert records of the RDD (people) to Rows. val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim)) // Apply the schema to the RDD. val peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema) // Register the DataFrames as a table. peopleDataFrame.registerTempTable("people") // SQL statements can be run by using the sql methods provided by sqlContext. val results = sqlContext.sql("SELECT name FROM people")
2.各种数据文件,包括json、parquet、orc等,比如json数据集
val df = sqlContext.read.json("examples/src/main/resources/people.json")
3.外部数据库
val jdbcDF = sqlContext.read.format("jdbc").options( Map("url" -> "jdbc:postgresql:dbserver", "dbtable" -> "schema.tablename")).load()
我在调试时最常用的方法如下
sqlContext.createDataFrame(Seq((1,"a"),(2,"b")))原文:http://www.cnblogs.com/lybo/p/6254594.html