1.官网
kafka.apache.org
2.上传
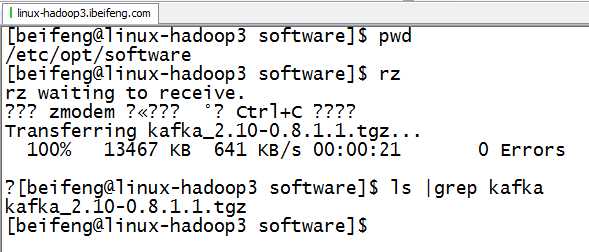
3.解压到modules
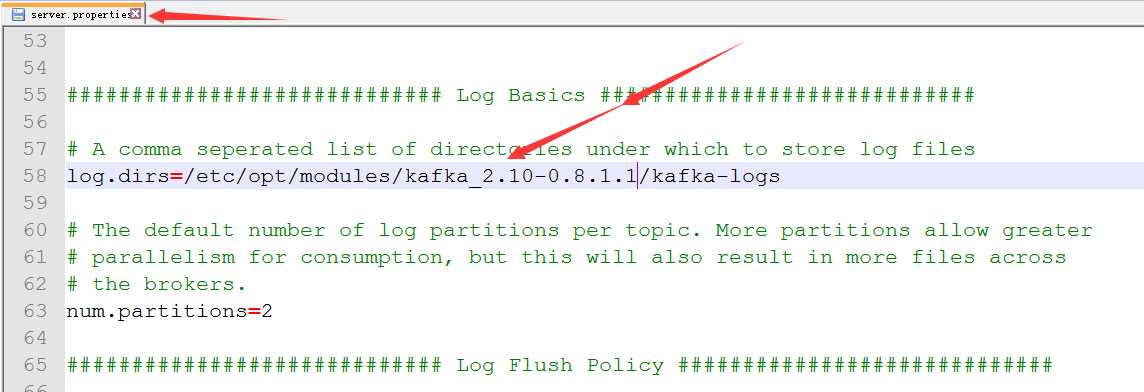
4.修改配置文件server.properties
)修改kafa收集到的日志数据存储文件夹
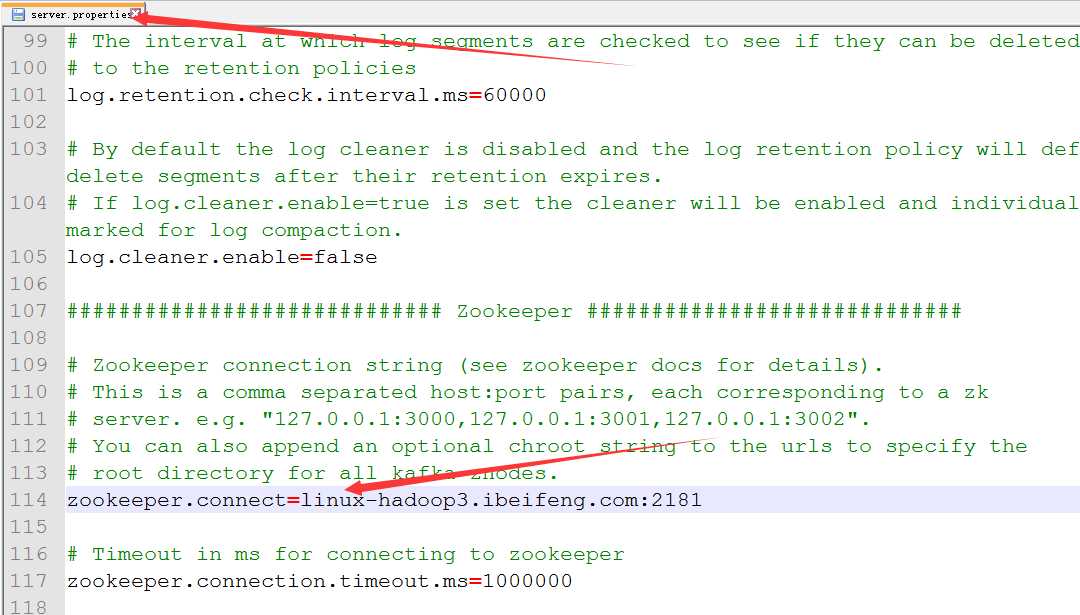
)修改zookeeper
二:启动
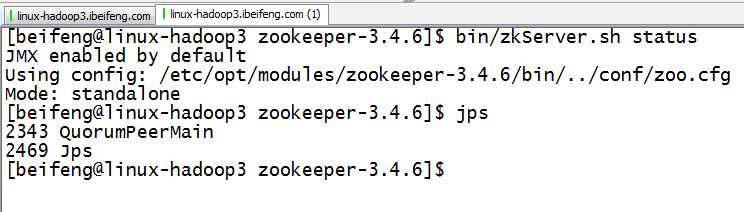
1.启动zookeeper
2.启动broker
如果没有出现日志错误,就使用下面的命令:
nohup bin/kafka-server-start.sh config/server.properties > logs/server-start.log 2>&1 &
3.检验
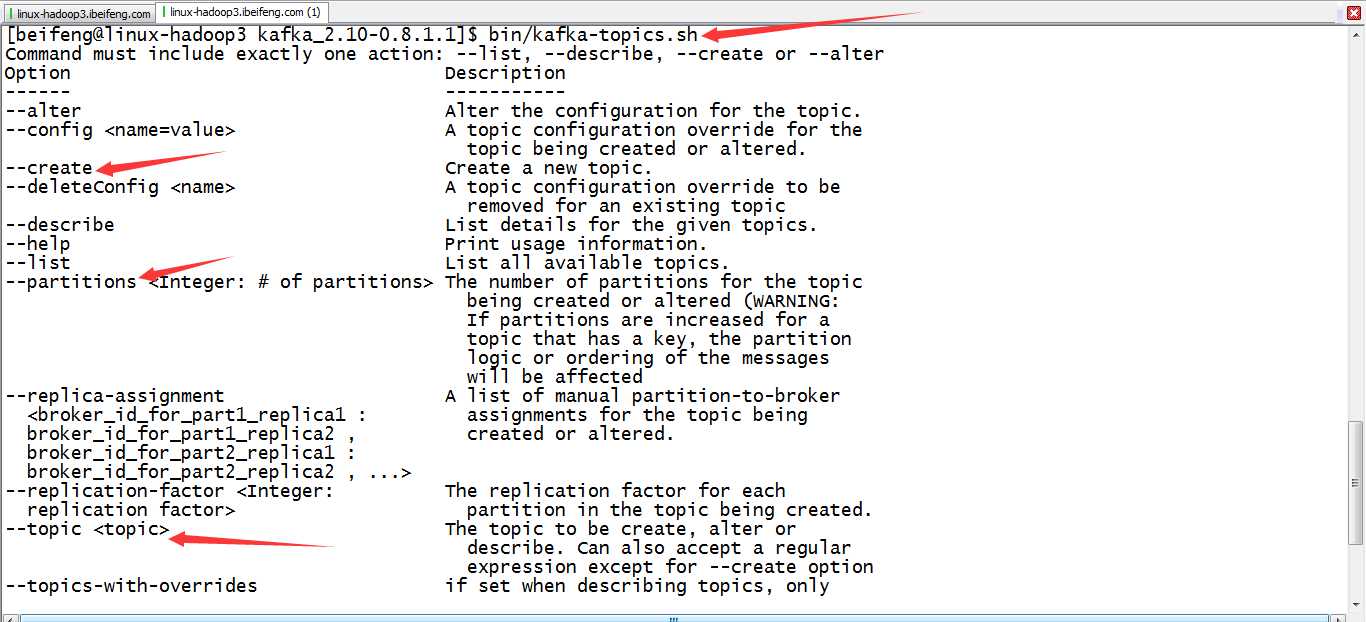
4.创建topic(使用help帮助)
5.创建一个nginxlog的topic
bin/kafka-topics.sh --create --topic nginxlog --partitions 1 --replication-factor 1 --zookeeper linux-hadoop3.ibeifeng.com:2181

6.查看详情
bin/kafka-topics.sh --describe --topic nginxlog --zookeeper linux-hadoop3.ibeifeng.com:2181

三:检测topic
1.启动消息生产者,将消息发送到kafka的topic上
bin/kafka-console-producer.sh --broker-list linux-hadoop3.ibeifeng.com:9092 --topic nginxlog

2.启动消息消费者
bin/kafka-console-consumer.sh --zookeeper linux-hadoop3.ibeifeng.com:2181 --topic nginxlog --from-beginning

四:模拟产生nginx日志
1.在服务器上创建一个根目录
2.上传jar包
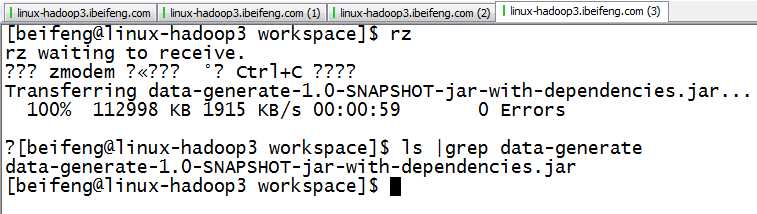
3.执行命令
java -jar data-generate-1.0-SNAPSHOT-jar-with-dependencies.jar 1000 >>nginx.log

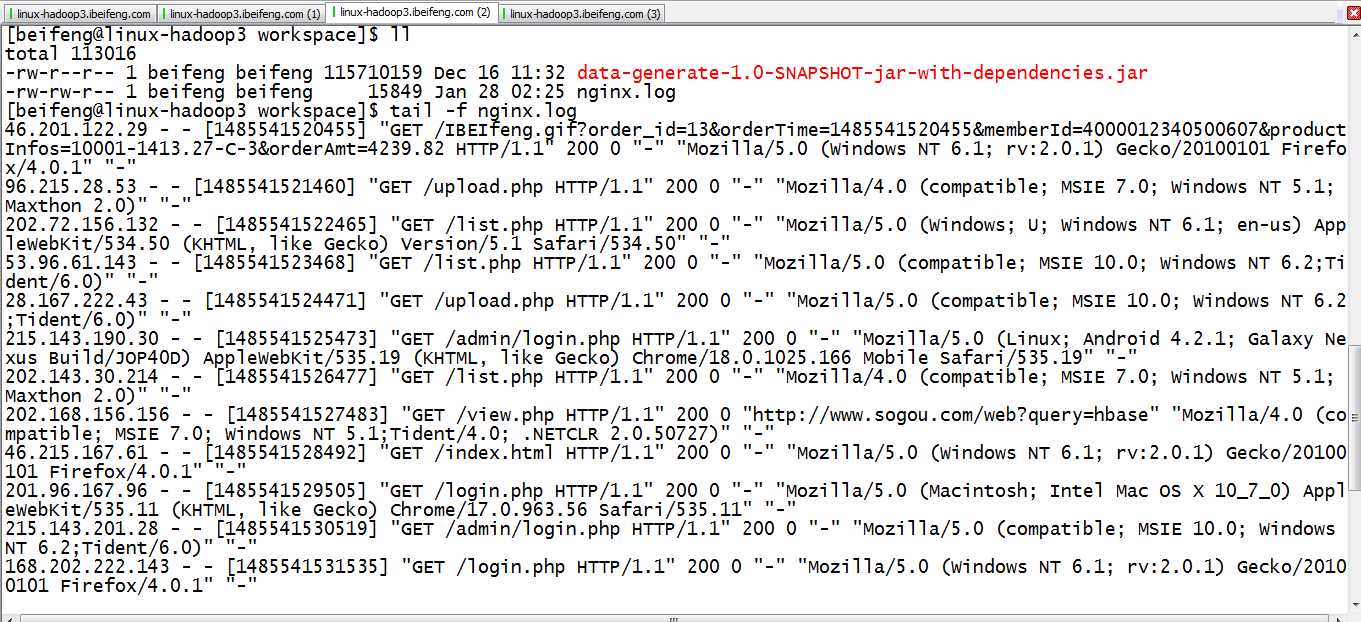
4.查看
tail -f nginx.log
五:使用flume将模拟产生的nginx日志上传到hdfs和kafka上
1.当前状态

2.project_agent.conf
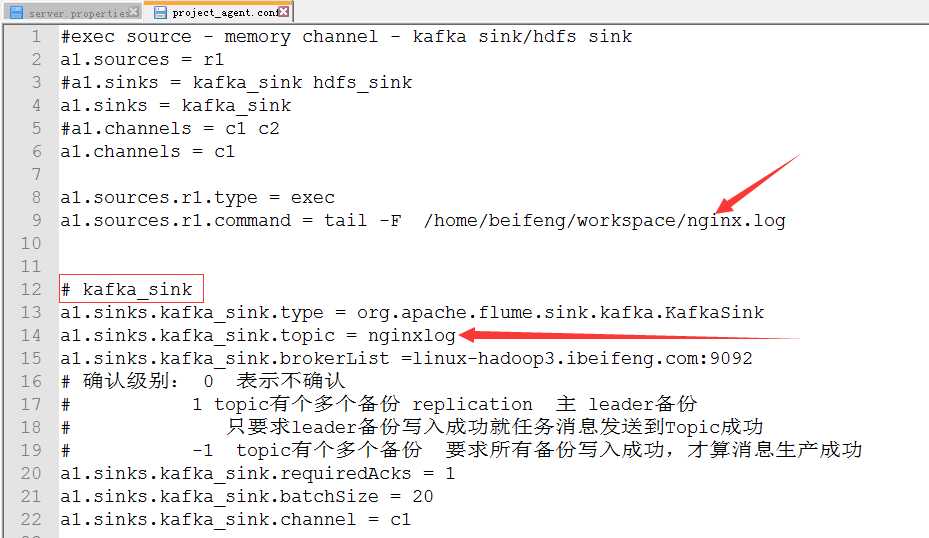
3.具体的代码

1 #exec source - memory channel - kafka sink/hdfs sink 2 a1.sources = r1 3 #a1.sinks = kafka_sink hdfs_sink 4 a1.sinks = kafka_sink 5 #a1.channels = c1 c2 6 a1.channels = c1 7 8 a1.sources.r1.type = exec 9 a1.sources.r1.command = tail -F /home/beifeng/workspace/nginx.log 10 11 12 # kafka_sink 13 a1.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink 14 a1.sinks.kafka_sink.topic = nginxlog 15 a1.sinks.kafka_sink.brokerList =linux-hadoop3.ibeifeng.com:9092 16 # 确认级别: 0 表示不确认 17 # 1 topic有个多个备份 replication 主 leader备份 18 # 只要求leader备份写入成功就任务消息发送到Topic成功 19 # -1 topic有个多个备份 要求所有备份写入成功,才算消息生产成功 20 a1.sinks.kafka_sink.requiredAcks = 1 21 a1.sinks.kafka_sink.batchSize = 20 22 a1.sinks.kafka_sink.channel = c1 23 24 # hdfs_sink 25 #a1.sinks.hdfs_sink.type = hdfs 26 #a1.sinks.hdfs_sink.hdfs.path = /flume/events/%Y%m%d 27 #a1.sinks.hdfs_sink.hdfs.filePrefix = nginx_log- 28 #a1.sinks.hdfs_sink.hdfs.fileType = DataStream 29 #a1.sinks.hdfs_sink.hdfs.useLocalTimeStamp = true 30 #a1.sinks.hdfs_sink.hdfs.rollInterval = 0 31 #rollSize值 比hdfs block大小 小一点 (10M) 32 #a1.sinks.hdfs_sink.hdfs.rollSize = 102400 33 #a1.sinks.hdfs_sink.hdfs.rollCount = 0 34 35 36 # Use a channel which buffers events in memory 37 a1.channels.c1.type = memory 38 a1.channels.c1.capacity = 1000 39 a1.channels.c1.transactionCapacity = 100 40 41 #a1.channels.c2.type = memory 42 #a1.channels.c2.capacity = 1000 43 #a1.channels.c2.transactionCapacity = 100 44 45 # Bind the source and sink to the channel 46 #a1.sources.r1.channels = c1 c2 47 #a1.sinks.kafka_sink.channel = c1 48 #a1.sinks.hdfs_sink.channel = c2 49 #指定source 与 channel之间的关系 复制(默认) --- 多路复用模式 event header body 50 #a1.sources.r1.selector.type = replicating 51 52 ######################################################### 53 # Bind the source and sink to the channel 54 a1.sources.r1.channels = c1 55 a1.sinks.kafka_sink.channel = c1
六:具体情况
1.执行flume
bin/flume-ng agent -n a1 -c conf/ --conf-file conf/project_agent.conf -Dflume-root-logger=INFO,console

2.启动生产者,就是模拟问价jar
让其不断的产生日志到nginx.log中

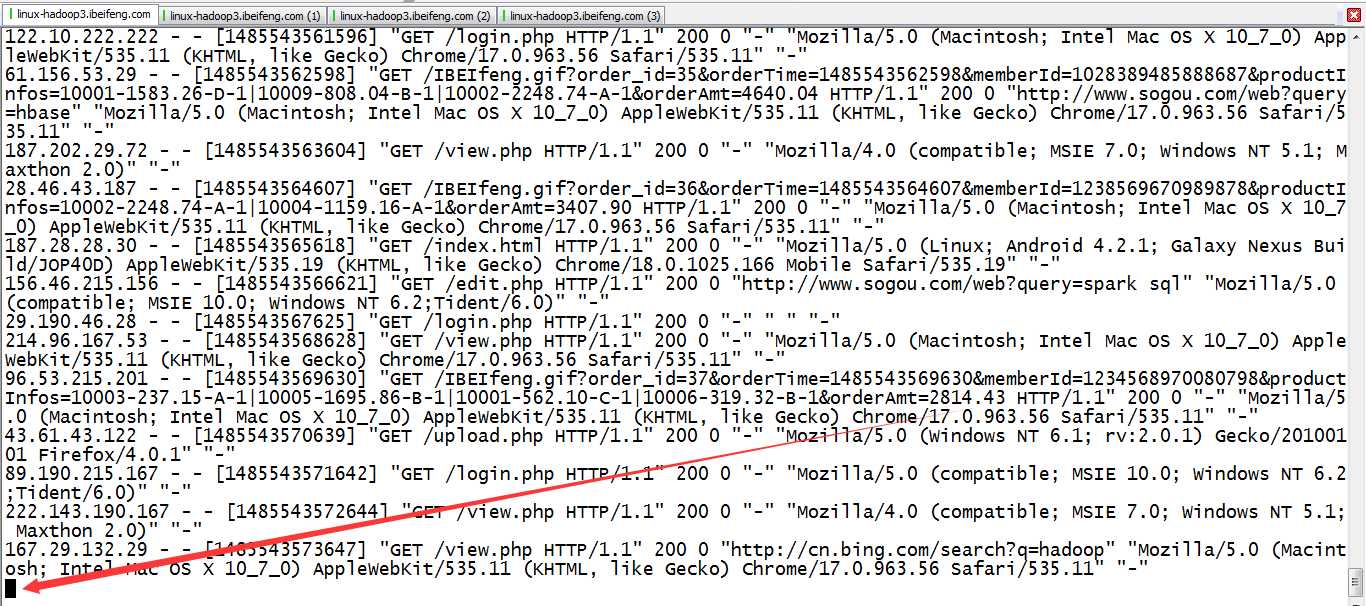
3.观看启动了消费者的窗口
就会发现不断的产生日志被消费
七:注意
1.关闭kafka

原文:http://www.cnblogs.com/juncaoit/p/6358007.html
