本系列意在长期连载分享,内容上可能也会有所删改;
因此如果转载,请务必保留源地址,非常感谢!
博客园:http://www.cnblogs.com/data-miner/(暂时公式显示有问题)
其他:建设中…
在Estlick, Mike, et al. "Algorithmic transformations in the implementation of K- means clustering on reconfigurable hardware." 2001中,作者将K-means算法用在FPGA板子中。在传统K-means中,用到了浮点数运算与乘法运算,而这两种运算在FPGA中非常耗时。为了能在FPGA中高效使用K-means算法,作者提出了修改的K-means算法。
先介绍一下明氏距离(Minkowski Distance),其定义如下
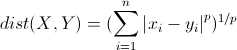
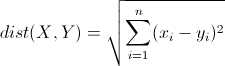
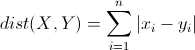

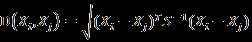
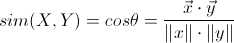
作者表示在FPGA中,欧氏距离的计算量太大,他希望用“曼哈顿距离”和“切比雪夫距离”替代。下图表示,空间中两个聚类中心,使用不同距离的分界面
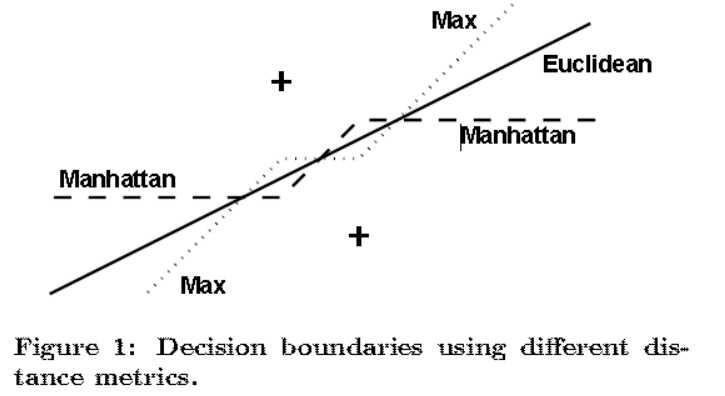
单独使用“曼哈顿距离”和“切比雪夫距离”都无法很好地替代“欧氏距离”,于是作者将两者融合,并说明效果的下降在允许范围内,而计算量大大降低。(想法很有趣)
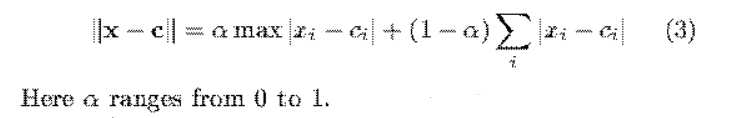
在Kanungo, Tapas, et al. "An Efficient k-Means Clustering Algorithm: Analysis and Implementation." 2002中,面对K-means运算量较大的问题,作者提出了“KD树”加速K-means算法的方法。
但是,其方法基本跟Pelleg, et al. "Accelerating exact k -means algorithms with geometric reasoning." 1999.没什么区别。此处不再赘述。
在Lee, Sangkeun, and M. H. Hayes. "Properties of the singular value decomposition for efficient data clustering." 2004中,作者对SVD的性质进行了讨论,并表示这些性能能加快K-means的过程。
作者首先给出了对数据集A进行SVD的解释
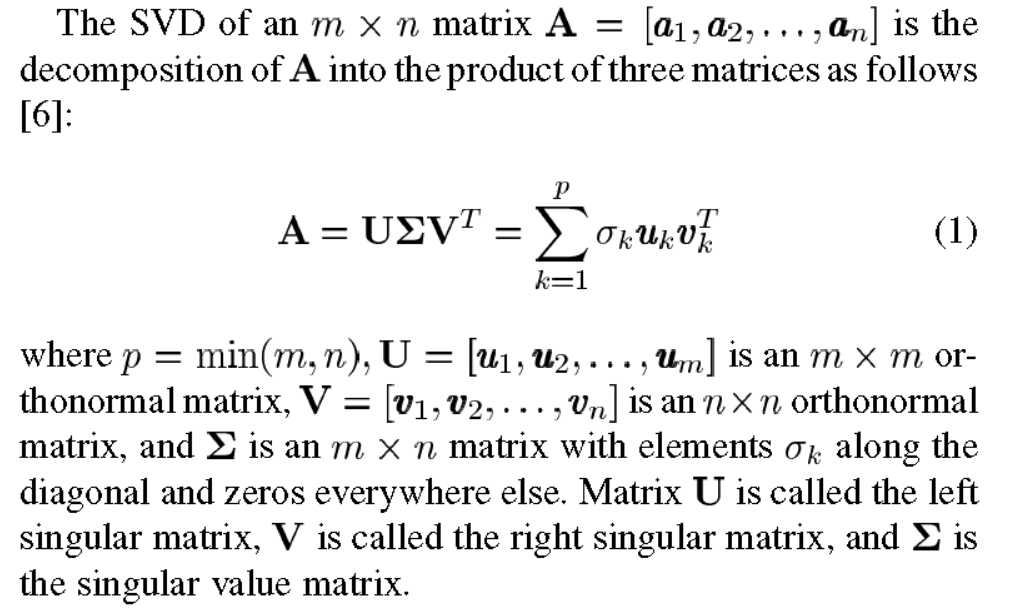
然后给出了本文最主要的公式,即A中每两个向量的欧氏距离,可以用对应的“右奇异向量”的加权和表示。(注:这里我们进一步分析,由于A是一个m?n的矩阵,V是一个n?n的矩阵,若要SVD分解后能加速K-means,至少要求m>n,即样本维数大于样本数量,然而这种情况比较少见。同时,SVD分解本身也是个非常耗时的操作。因此此方法更多的是提供一种思考方式。)
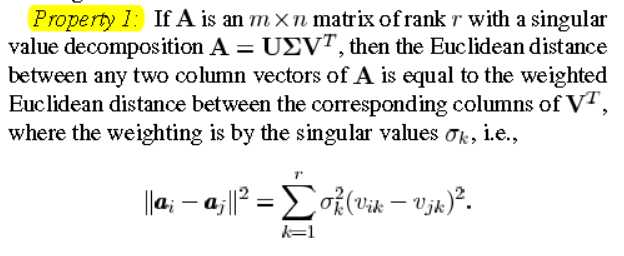
本文还给出了一种设置聚类中心数量K的方法。本质跟PCA类似,就是计算数据集A的主要能量聚集在多少维度上。区别是PCA需要的是这几个维度对应的向量,而这里只需要维度的数量。

文中还有更多利用SVD加速K-means聚类的细节,不再赘述
在Huang, Joshua Zhexue, et al. "Automated Variable Weighting in k-Means Type Clustering." 2005中,作者针对K-means算法中,每一维特征在聚类结果中权重相同的情况,提出了修改的K-mwans。
作者首先提出,在数据挖掘过程中,往往数据的维数都是成百上千,而其中对分析有意义的维数只是部分。以往根据经验给每一维数据赋权重,作者提出一种算法来自动求出权重。
先给出原始K-means的损失函数,即最小均方误差


然后作者给出修改的K-means的损失函数。本质就是在损失函数里增加了权重,然后继续通过EM算法求解。在最小均方误差的约束下,类内距离小的那一维特征会被赋予较大的权重,类内距离较大的则会被赋予较小的权重。即作者所说的,自动求解权重
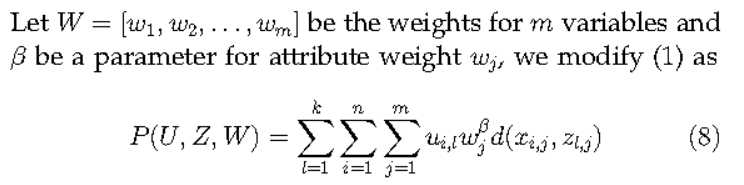
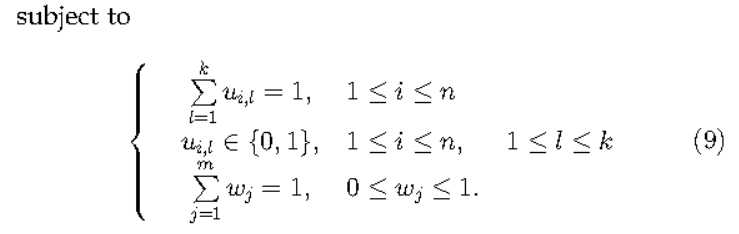
关于详细的求解步骤,与收敛性的证明,可以参考原论文
在Kuncheva, L. I., and D. P. Vetrov. "Evaluation of Stability of k-Means Cluster Ensembles with Respect to Random Initialization." 2006中,作者研究了通过Ensembling来提升K-means等算法的稳定性
作者先明确了研究的问题,即
作者给出了Ensembling的方法,即把数据分成L组,再分别对L组的数据进行聚类,并将结果融合

对于上述问题,作者都没有给出理论证明,都是实验上的说明:
在Arthur, David, and S. Vassilvitskii. "k-means++: the advantages of careful seeding." 2015中,作者提出了K-means++算法,也是较为常用的K-means修改算法之一。这个算法主要提出了一种选择初始化聚类中心的方法,并从理论上证明了这个方案会使收敛更快,且效果更好

在Chiang, Ming Tso, and B. Mirkin. "Intelligent Choice of the Number of Clusters in K-Means Clustering: An Experimental Study with Different Cluster Spreads." 2010中,针对K-means算法中聚类中心数量难以确定的问题,作者通过实验的方式,比较了多种估计K-means聚类中心数量的方法。并通过实验对比了这些方法在估计类别数量、中心、标记时的准确度。


为了选择对照算法,作者总结了其他估计聚类数量K的算法。针对不同类型的方法,作者也给出了例子。有兴趣的同学可以参考原文。
基于变化的算法:即定义一个函数,认为在正确的K时会产生极值。
基于结构的算法:即比较类内距离、类间距离以确定K。
基于一致性矩阵的算法:即认为在正确的K时,不同聚类的结果会更加相似,以此确定K。
基于层次聚类:即基于合并或分裂的思想,在一定情况下停止获得K。
基于采样的算法:即对样本采样,分别做聚类;根据这些结果的相似性确定K。
最后通过对比实验,作者给出结论认为Intelligent K-means能较为有效的估计真实聚类中心、以及样本所属类别。同时,Intelligent K-means对类别数量的估计普遍较大。不过由于实验是在高斯分布的仿真实验下进行的,结论并非我所关注,不再赘述。
原文:http://www.cnblogs.com/data-miner/p/6288227.html