今天看了一下正则,以前总是觉得很繁琐懒得看,今天看了一下,觉得还是挺有趣的
A* 0或多个A
A? 0或一个A
A+ 1或多个A


\d是匹配所有数字,但是java是默认对 \有处理的,所以我们需要反义一下,即加\
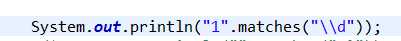

[]中存在的是匹配的规则
如:
[A-Za-z] 匹配A-Z和a-z所有的字母
{}中存放的是需要匹配字符的个数
如:
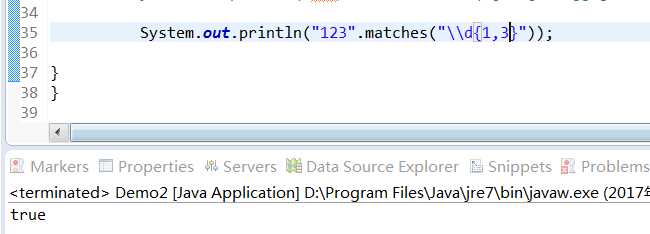
[\\d] 匹配数字但只能匹配一个
但加上[\\d]{1,3}就能匹配1到3个字符为数字
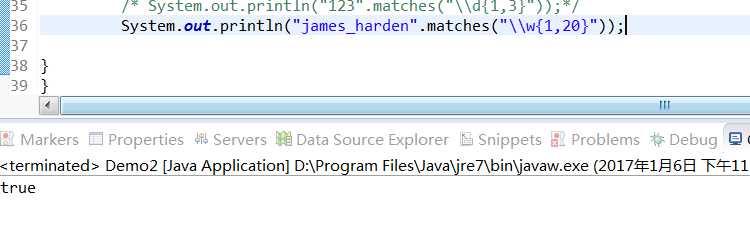
\w 为匹配英文名称格式 A-Za-z_0-9
\W取反
\d 为匹配所有数字即0-9
\D 不匹配数字
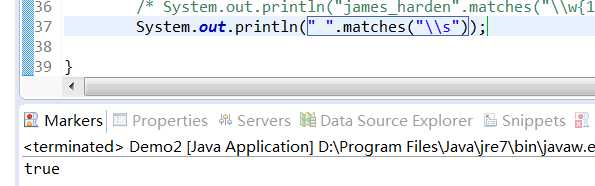
\s 匹配空格符
\S 不匹配空格符
pattern 我理解就是储存需要匹配的规则
matcher 是校验字符的结果
一般的格式是:
Pattern p=Pattern.compile("\\d{1,3}");
Matcher m=p.matcher("123");
System.out.println(m.matches()); 输入匹配结果
m.matches() 匹配整个字符串校验
m.find() 寻找字符串中符合 规则的字符串
m.lookingAt() 始终匹配前面的字符串
将找到的目标字符串替换并将找到之前的字符串一起存入新的字符串中
可以结合m.find()来使用
如
String words="i like java ,java like me,but my mom hate jaVa,because i almost lose myself in Java sometimes";
我想把奇数的java大写
Pattern p=Pattern.compile("java",Pattern.CASE_INSENSITIVE); //这边不区分大小写,都能匹配
Matcher m=p.matcher(words);
StringBuffer sb=new StringBuffer(); //用来存放修改好的字符串
int count=0; //用来统计奇偶
while(m.find){
if(i%2==0){
m.appendrReplacement(sb,"java");
}else{
m.appendReplacement(sb,"JAVA");
}
}
这里最重要的一点事 m.appendReplacement 值能将匹配的字符前面的一起加入的新的字符串中,但是最后的字符无法处理所以这边 Matcher还提供了一个方法
m.appendTail(sb); //这里就是将小尾巴也加入的 字符串中
System.out.println(sb); //这边再输出就是全部的字符串了
这个返回的就是我们匹配的字符
将查询到的 字符串,按规则分组
如 规则为 "(\\d{1,2})([a-z]{12})" //这里有两个规则,如果需要分组的话,需要用()将2个规则分割开
小例子 微形爬虫
将文件中是邮箱类型的信息爬出,并存放到一个新的文件中
一般邮箱为:XXX@xxx.xxx 或者xxx@xxx.xxx.xxx
所以这边规则 可以写为 "\\w+@[A-Za-z0-9]+\\.[A-Za-z]+\\.?[A-Za-z]*" 正则中 . 为 \. 所以在java中转义后为\\.

原文:http://www.cnblogs.com/lrStudyRecords/p/6258146.html