昨天本博客受到了xss跨站脚本注入攻击,3分钟攻陷……其实攻击者进攻的手法很简单,没啥技术含量。只能感叹自己之前竟然完全没防范。
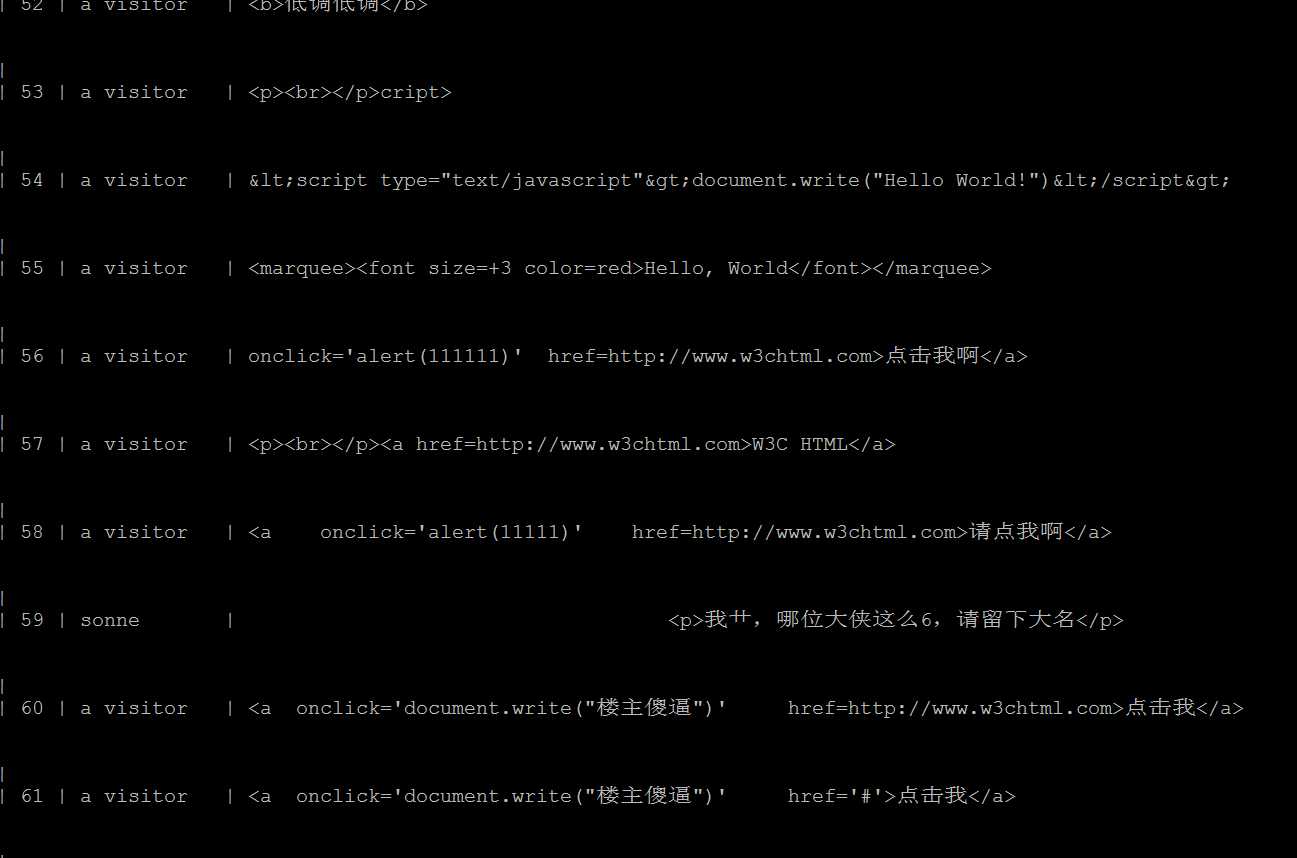
这是数据库里留下的一些记录。最后那人弄了一个无线循环弹出框的脚本,估计这个脚本之后他再想输入也没法了。
类似这种:
<html>
<body onload=‘while(true){alert(1)}‘>
</body>
</html>
我立刻认识到这事件严重性,它说明我的博客有严重安全问题。因为xss跨站脚本攻击可能导致用户Cookie甚至服务器Session用户信息被劫持,后果严重。虽然攻击者就用些未必有什么技术含量的脚本即可做到。
第二天花些时间去了解,该怎么防范。顺便也看了sql注入方面。
sql注入是源于sql语句的拼接。所以需要对用户输入参数化。由于我使用的是jpa,不存在sql拼接问题,但还是对一些用户输入做处理比较好。我的博客系统并不复杂,一共四个表,Article,User,Message,Comment。
涉及数据库查询且由用户输入的就只有用户名,密码,文章标题。其它后台产生的如文章日期一类就不用管。
对于这三个字段的校验,可以使用自定义注解方式。
/**
* @ClassName: IsValidString
* @Description: 自定义注解实现前后台参数校验,判断是否包含非法字符
* @author 无名
* @date 2016-7-25 下午8:22:58
* @version 1.0
*/
@Target({ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = IsValidString.ValidStringChecker.class)
@Documented
public @interface IsValidString
{
String message() default "The string is invalid.";
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default{};
class ValidStringChecker implements ConstraintValidator<IsValidString,String>
{
@Override
public void initialize(IsValidString arg0)
{
}
@Override
public boolean isValid(String strValue, ConstraintValidatorContext context)
{
//校验方法添在这里
return true;
}
}
}
定义了自定义注解以后就可以在对应的实体类字段上添上@IsValidString即可。
但由于我还没研究出怎么拦截自定义注解校验返回的异常,就在controller类里做校验吧。
public static boolean contains_sqlinject_illegal_ch(String str_input) {
//"[`~!@#$%^&*()+=|{}‘:;‘,\\[\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。,、?]"
String regEx = "[‘=<>;\"]";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(str_input);
if (m.find()) {
return true;
} else {
return false;
}
}
拦截的字符有 ‘ " [] <> ;
我觉得这几个就够了吧。<>顺便就解决了xxs跨站脚本注入问题。
而xxs跨站脚本注入问题还是让我很头疼。因为我的博客系统使用wangEditor web文本编辑器,返回给后台的包含很多合法的html标签,用来表现文章格式。所以不能统一过滤<>这类字符。
例如,将<html><body onload=‘while(true){alert(1)}‘></body></html>这句输入编辑器,提交。后台得到的是:
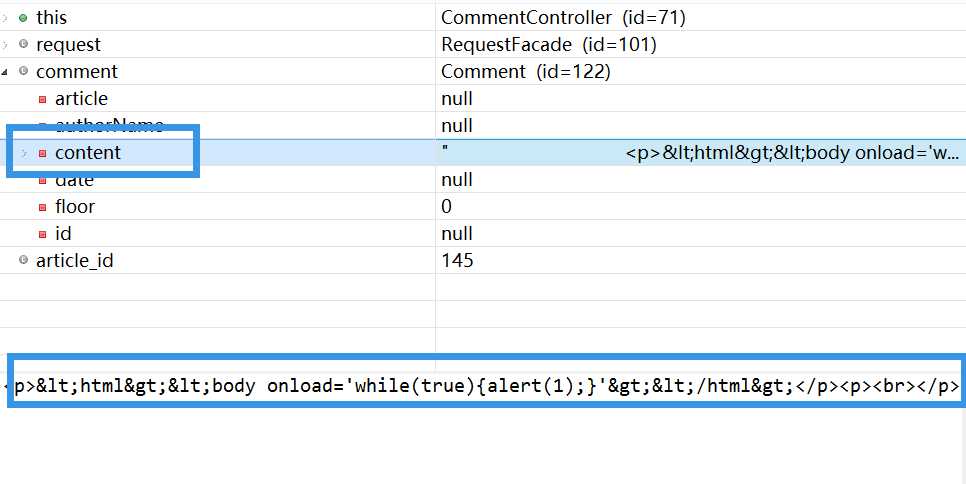
中间被转意的<,>是合法的可供页面显示的<>字符。而外面的<p><br>就是文本编辑器生产的用来控制格式的正常的html标签。
问题在于,如果有人点击编辑器“源代码”标识,将文本编辑器生产的正常的html标签,再输入这句<html><body onload=‘while(true){alert(1)}‘></body></html>结果返回后台的就是原封不动的<html><body onload=‘while(true){alert(1)}‘></body></html> <和>没有变成<和>。
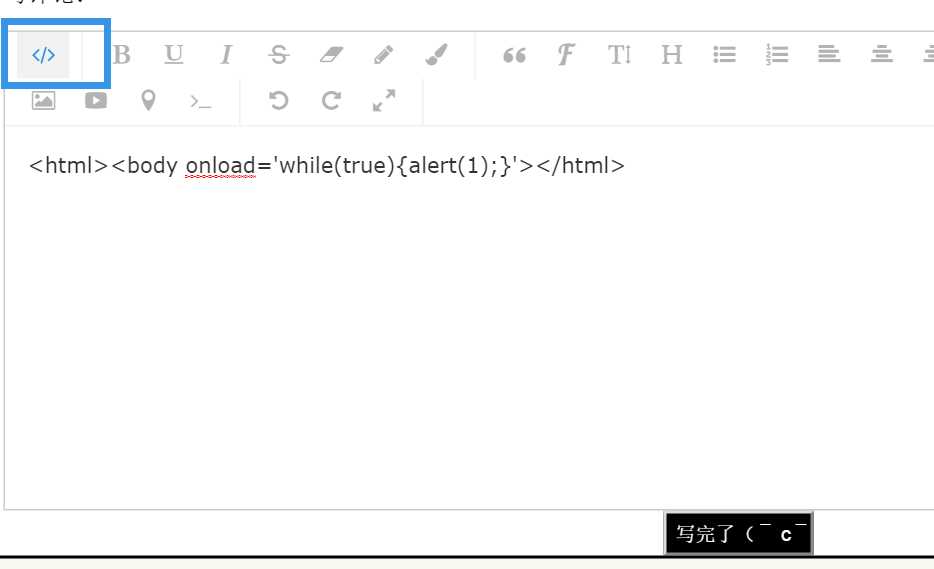
这让人头痛,我在想这个编辑器为什么提供什么狗屁查看源代码功能,导致不能统一对<>。
在这种情况下,我只能过滤一部分认准是有危害的html标签,而众所周知,这类黑名单校验是不够安全的。(2016-12-30:下面这个函数是肯定不行的,写的很蠢,下文已经把它干掉,用白名单校验,并应用正则表达式的方式来做)
/*
* Cross-site scripting (XSS) is a type of computer security vulnerability
* typically found in web applications. XSS enables attackers to inject
* client-side scripts into web pages viewed by other users. A cross-site
* scripting vulnerability may be used by attackers to bypass access
* controls such as the same-origin policy. Cross-site scripting carried out
* on websites accounted for roughly 84% of all security vulnerabilities
* documented by Symantec as of 2007. Their effect may range from a petty
* nuisance to a significant security risk, depending on the sensitivity of
* the data handled by the vulnerable site and the nature of any security
* mitigation implemented by the site‘s owner.(From en.wikipedia.org)
*/
public static boolean contains_xss_illegal_str(String str_input) {
if (str_input.contains("<html") || str_input.contains("<HTML")
|| str_input.contains("<body") || str_input.contains("<BODY")
|| str_input.contains("<script")
|| str_input.contains("<SCRIPT") || str_input.contains("<link")
|| str_input.contains("<LINK")
|| str_input.contains("%3Cscript")
|| str_input.contains("%3Chtml")
|| str_input.contains("%3Cbody")
|| str_input.contains("%3Clink")
|| str_input.contains("%3CSCRIPT")
|| str_input.contains("%3CHTML")
|| str_input.contains("%3CBODY")
|| str_input.contains("%3CLINK") || str_input.contains("<META")
|| str_input.contains("<meta") || str_input.contains("%3Cmeta")
|| str_input.contains("%3CMETA")
|| str_input.contains("<style") || str_input.contains("<STYLE")
|| str_input.contains("%3CSTYLE")
|| str_input.contains("%3Cstyle") || str_input.contains("<xml")
|| str_input.contains("<XML") || str_input.contains("%3Cxml")
|| str_input.contains("%3CXML")) {
return true;
} else {
return false;
}
}
我在考虑着把这个文本编辑器的查看源代码功能给干掉。
另外,还是要系统学习xss跨站脚本注入防范。开始看一本书《白帽子讲web安全》,觉得这本书不错。
到时候有新见解再在这篇文章补充。
2016-12-30日补充:
今天读了那本《白帽子讲web安全》,果然获益不少。其中提到富文本编辑器的情况,由于富文本编辑器本身会使用正常的一些html标签,所以需要做白名单校验。只允许使用一些确定安全的标签,除富文本编辑器使用的标签,其他的都过滤掉。这是白名单方式,是真正合理的。
另外下午研究下正则表达式的写法:<([^(a)(img)(div)(p)(span)(pre)(br)(code)(b)(u)(i)(strike)(font)(blockquote)(ul)(li)(ol)(table)(tr)(td)(/)][^>]*)>(2016-12-30夜-2016-12-31 发现这个正则有误,下面就继续补充)
[^]是非的意思。
上面的正则的意思就是若含有a、img、div……之外的标签则匹配。
/*
* Cross-site scripting (XSS) is a type of computer security vulnerability
* typically found in web applications. XSS enables attackers to inject
* client-side scripts into web pages viewed by other users. A cross-site
* scripting vulnerability may be used by attackers to bypass access
* controls such as the same-origin policy. Cross-site scripting carried out
* on websites accounted for roughly 84% of all security vulnerabilities
* documented by Symantec as of 2007. Their effect may range from a petty
* nuisance to a significant security risk, depending on the sensitivity of
* the data handled by the vulnerable site and the nature of any security
* mitigation implemented by the site‘s owner.(From en.wikipedia.org)
*/
public static boolean contains_xss_illegal_str(String str_input) {
final String REGULAR_EXPRESSION =
"<([^(a)(img)(div)(p)(span)(pre)(br)(code)(b)(u)(i)(strike)(font)(blockquote)(ul)(li)(ol)(table)(tr)(td)(/)][^>]*)>";
Pattern pattern = Pattern.compile(REGULAR_EXPRESSION);
Matcher matcher = pattern.matcher(str_input);
if (matcher.find()) {
return true;
} else {
return false;
}
}
2016-12-30夜-2016-12-31 补充:
实验发现前面写的那个正则表达式是无效的。同时发现这个正则是非常难写、很有技术含量的,对于我这个基本正则都不太熟悉的菜鸟来说。
这种‘非’的表达,不能简单的用上面提到的[^]。那种无法匹配字符串的非。例如(a[^bc]d)表示地是ad其中的字符串不能为b或c。
对于字符串的非,应该用这种表达式:^(?!.*helloworld).*$
以此为前提,下面的正则可以表达不为<p>的html标签:
<((?!p)[^>])> 后面[^]表示<>中只有一个字符(?!p)且第一个字符非p
若写成<((?!p)[^>]*)>则表示有n个字符,且第一个字符非p
@Test
public void test_Xss_check() {
System.out.println("begin");
String str_input = "<p>";
final String REGULAR_EXPRESSION = "<((?!p)[^>])>";
Pattern pattern = Pattern.compile(REGULAR_EXPRESSION);
Matcher matcher = pattern.matcher(str_input);
if (matcher.find()) {
System.out.println("yes");
}
}
那么该如何匹配,不为AA且不为BB的html标签呢?
<((?!p)(?!a)[^>]*)>匹配的就是不以p开头且不以a开头html标签!
我们要求的匹配的是:不为<b>、不为<ul>、不为<li>……且不以<a 开头、不以<img 开头、不以</开头……的html标签。该如何写?
先写一个简单的例子:<(((?!p )(?!a )[^>]*)((?!p)(?!a).))>匹配的是非<p xxxx>且非<a xxxx>且非<p>且非<a>的<html>标签。
例如,字符串<pasd>则匹配,<p asd>则不匹配,<p>则不匹配。然而不精准的一点是,<ppp>或<aaa>也不匹配。其他问题也有,例如非<table>的标签就不知道该怎么表示。
总之感觉这个正则很难写,超出了我的能力范围。所以最后决定用正则先筛选html标签,再由java代码做白名单筛选。
用于筛选html标签的正则是<(?!a )(?!p )(?!img )(?!code )(?!spab )(?!pre )(?!font )(?!/)[^>]*>,筛选到的html排除掉<a xxx><p xxx><img xx></>等等,因为那些是默认合法的。筛选得到的<html>标签存进List里,再做白名单校验。
代码如下:
@Test public void test_Xss_check() { String str_input = "<a ss><script>sds<body><a></adsd><d/s><p dsd><pp><a><dsds>dsdas<font ds>" + "<fontdsdsd><font>das<oooioacc><pp sds><script><code ><br><code><ccc><abug>"; System.out.println("String inputed:" + str_input); final String REGULAR_EXPRESSION = "<(?!a )(?!p )(?!img )(?!code )(?!spab )(?!pre )(?!font )(?!/)[^>]*>"; final Pattern PATTERN = Pattern.compile(REGULAR_EXPRESSION); final Matcher MATCHER = PATTERN.matcher(str_input); List<String> str_lst = new ArrayList<String>(); while (MATCHER.find()) { str_lst.add(MATCHER.group()); } final String LEGAL_TAGS = "<a><img><div><p><span><pre><br><code>" + "<b><u><i><strike><font><blockquote><ul><li><ol><table><tr><td>"; for (String str:str_lst) { if (!LEGAL_TAGS.contains(str)) { System.out.println(str + " is illegal"); } } }
上述代码输出为:
String inputed:<a ss><script>sds<body><a></adsd><d/s><p dsd><pp><a><dsds>dsdas<font ds><fontdsdsd><font>das<oooioacc><pp sds><script><code ><br><code><ccc><abug>
<script> is illegal
<body> is illegal
<d/s> is illegal
<pp> is illegal
<dsds> is illegal
<fontdsdsd> is illegal
<oooioacc> is illegal
<pp sds> is illegal
<script> is illegal
<ccc> is illegal
<abug> is illegal
个人网站对xss跨站脚本攻击(重点是富文本编辑器情况)和sql注入攻击的防范
原文:http://www.cnblogs.com/rixiang/p/6239464.html