给定任意D,它是某些H的Bad Sample(即Ein和Eout不接近)的概率为:
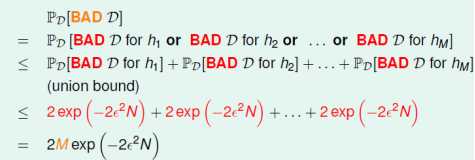
即H中备选函数的数量M=|H|越少,样本数据量N越大,则样本成为坏样本的概率越小。在一个可接受的概率水平上,学习算法A只需要挑选那个表现最好的h作为g就行了。
挑选出最好的g需要满足两个条件:找到一个假设g使得Eout(g)和Ein(g)是非常接近的,使得Ein(g)足够小,
下面是BAD和M的关系:

因此选择一个合适的M是非常重要的,需要用一个有限的值m来替代一个非常无限的值M
思路:overlapping for similar hypotheses h1 ≈ h2 ,它们的Ein(h1)≈Ein(h2),Eout(h1)≈Eout(h2)(比如说PLA中的两条直线,相邻的很近的直线)=>union bound over-estimating
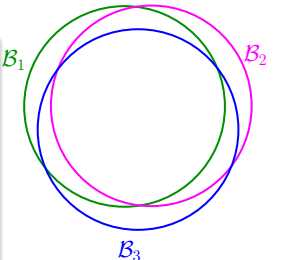
to account for overlap,we can group similar hypotheses by kind
h对D的一个Dichotomy(二分):备选函数集中的每一个函数h都是输入X到输出Y的一个映射:H={hypothesis h:X->{×,Ο}}将h(x1,x2,...,xN)=(h(x1),h(x2),...,h(xN))∈{×,Ο}N 其中H(x1,x2,...,xN)包含了所有对D的dichotomies。
hypotheses H 和dichotomies H(x1,x2,...,xN)的区别:

growth function: remove dependence by taking max of all possible (x1, x2, . . . , xN)
![]()
4个成长函数

break point:有k个输入,如果它不能被当前的备选函数集H shatter,那么k就是H的一个Break Point


无限的hypotheses 变成有限的dichotomies
原文:http://www.cnblogs.com/nolonely/p/6163720.html