#include <stdio.h>
#include <string.h>
char string[50],word[8],ch;
char keyword[][6]={"begin","if","then","while","do","end"};//关键字数组
int type,p,i,n,sum;
void getsym();
main()
{
p=0;
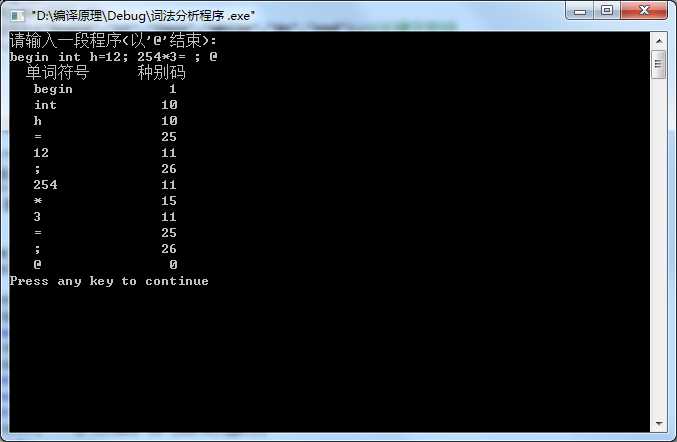
printf("请输入一段程序(以‘@‘结束):\n");
do{
scanf("%c",&ch);
string[p++]=ch;
}while(ch!=‘@‘);
printf(" 单词符号\t种别码 \n");
p=0;
do{
getsym();
switch(type)
{
case 11:
printf(" %-12d%6d\n",sum,type);
break;
case -1:
printf("此为无法识别的字符!\n");
return 0;
break;
default:
printf(" %-12s%6d \n",word,type);
break;
}
}while(type!=0);
return 0;
}
void getsym()
{
sum=0;
for(i=0;i<8;i++)
word[i++]= NULL;
ch=string[p++];
i=0;
while((ch==‘ ‘)||(ch==‘\n‘))
ch=string[p++];
if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))) //字母的判断
{
while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘)))
{
word[i++]=ch;
ch=string[p++];
}
p--;
type=10; //先将以字母开头的字符识别为标识符
for(n=0;n<6;n++)
if(strcmp(word,keyword[n])==0) //关键字数组的比较
{
type=n+1;
break;
}
}
else if((ch>=‘0‘)&&(ch<=‘9‘))
{
while((ch>=‘0‘)&&(ch<=‘9‘))
{
sum=sum*10+ch-‘0‘; //把字符型转化为整形sum
ch=string[p++];
}
p--;
type=11;
}
else //else语句内识别除关键字、标识符、数字以外的其他字符
{
switch(ch)
{
case ‘+‘:type=13;word[i++]=ch;break;
case ‘-‘:type=14;word[i++]=ch;break;
case ‘*‘:type=15;word[i++]=ch;break;
case ‘/‘:type=16;word[i++]=ch;break;
case ‘:‘:
word[i++]=ch;
ch=string[p++];
if(ch==‘=‘)
{
type=18;
word[i++]=ch;
}
else
{
type=18;
p--;
}
break;
case ‘<‘: //‘<‘和‘<=‘的判断
word[i++]=ch;
ch=string[p++];
if(ch==‘=‘)
{
type=21;
word[i++]=ch;
}
else
{
type=20;
p--;
}
break;
case ‘>‘: //‘>‘和‘>=‘的判断
word[i++]=ch;
ch=string[p++];
if(ch==‘=‘)
{
type=24;
word[i++]=ch;
}
else
{
type=23;
p--;
}
break;
case ‘=‘:type=25;word[i++]=ch;break;
case ‘;‘:type=26;word[i++]=ch;break;
case ‘(‘:type=27;word[i++]=ch;break;
case ‘)‘:type=28;word[i++]=ch;break;
case ‘@‘:type=0;word[i++]=ch;break;
default:type=-1;break;
}
}
word[i++]=‘\0‘; //把word字符数组变字符串
}
原文:http://www.cnblogs.com/H231/p/5937184.html