配置环境
包括
JAVA_HOME
jobmanager.rpc.address
jobmanager.heap.mb 和 taskmanager.heap.mb
taskmanager.numberOfTaskSlots
taskmanager.tmp.dirs
slaves文件
启动关闭
bin/start-cluster.sh
bin/stop-cluster.sh
初步使用 public static void main(String[] args) throws Exception { if (args.length != 2){ System.err.println("USAGE:\nSocketTextStreamWordCount <hostname> <port>"); return; } String hostName = args[0]; Integer port = Integer.parseInt(args[1]); // set up the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment(); // get input data DataStream<String> text = env.socketTextStream(hostName, port); DataStream<Tuple2<String, Integer>> counts = // split up the lines in pairs (2-tuples) containing: (word,1) text.flatMap(new LineSplitter()) // group by the tuple field "0" and sum up tuple field "1" .keyBy(0) .sum(1); counts.print(); // execute program env.execute("WordCount from SocketTextStream Example"); } public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // normalize and split the line String[] tokens = value.toLowerCase().split("\\W+"); // emit the pairs for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<String, Integer>(token, 1)); } } } }
编程步骤,和spark很类似 Obtain an execution environment, Load/create the initial data, Specify transformations on this data, Specify where to put the results of your computations, Trigger the program execution
连接flink的接口 StreamExecutionEnvironment getExecutionEnvironment() createLocalEnvironment() createRemoteEnvironment(String host, int port, String... jarFiles) Accumulators & Counters 用于求和和计数 步骤包括定义,添加到上下文,操作,最后获取 private IntCounter numLines = new IntCounter(); getRuntimeContext().addAccumulator("num-lines", this.numLines); this.numLines.add(1); myJobExecutionResult=env.execute("xxx"); myJobExecutionResult.getAccumulatorResult("num-lines")
并发数设置 System Level: parallelism.default=10 Client Level: ./bin/flink run -p 10 example.jar client.run(program, 10, true); Execution Environment Level: env.setParallelism(3); Operator Level: DataStream<Tuple2<String, Integer>> wordCounts = text .flatMap(new LineSplitter()) .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1).setParallelism(5);
最后上架构图和执行流程图,看起来和spark很类似
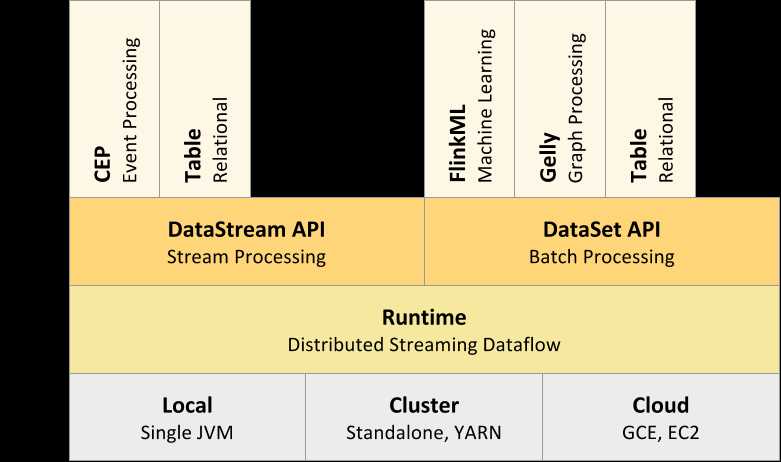
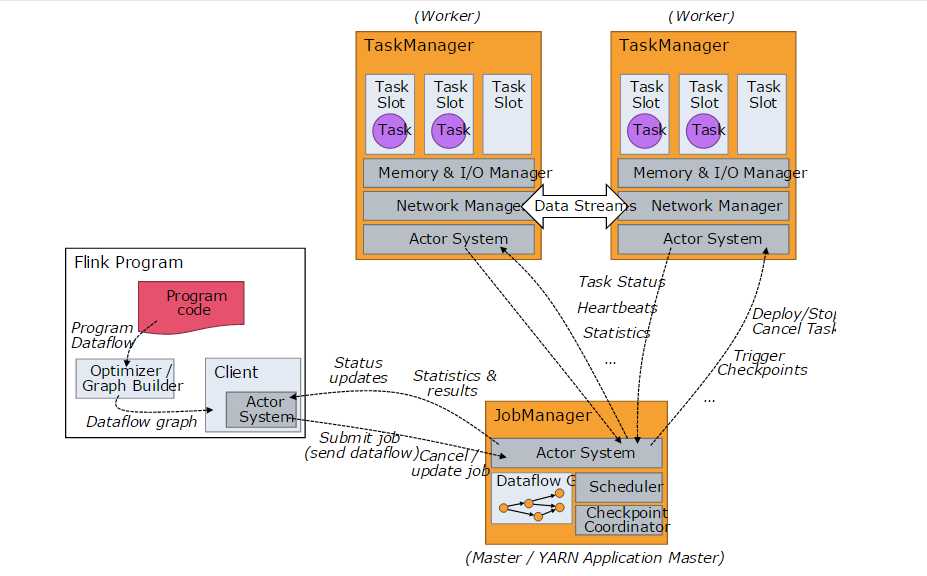
原文:http://www.cnblogs.com/fyzjhh/p/5347533.html