场景:
一个大小为100T的文件,统计单词"ERROR"和"INFO"的个数
普通做法
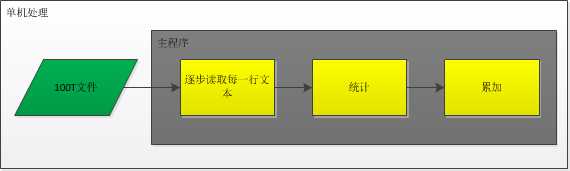
是不是效率太低了?
换个方式
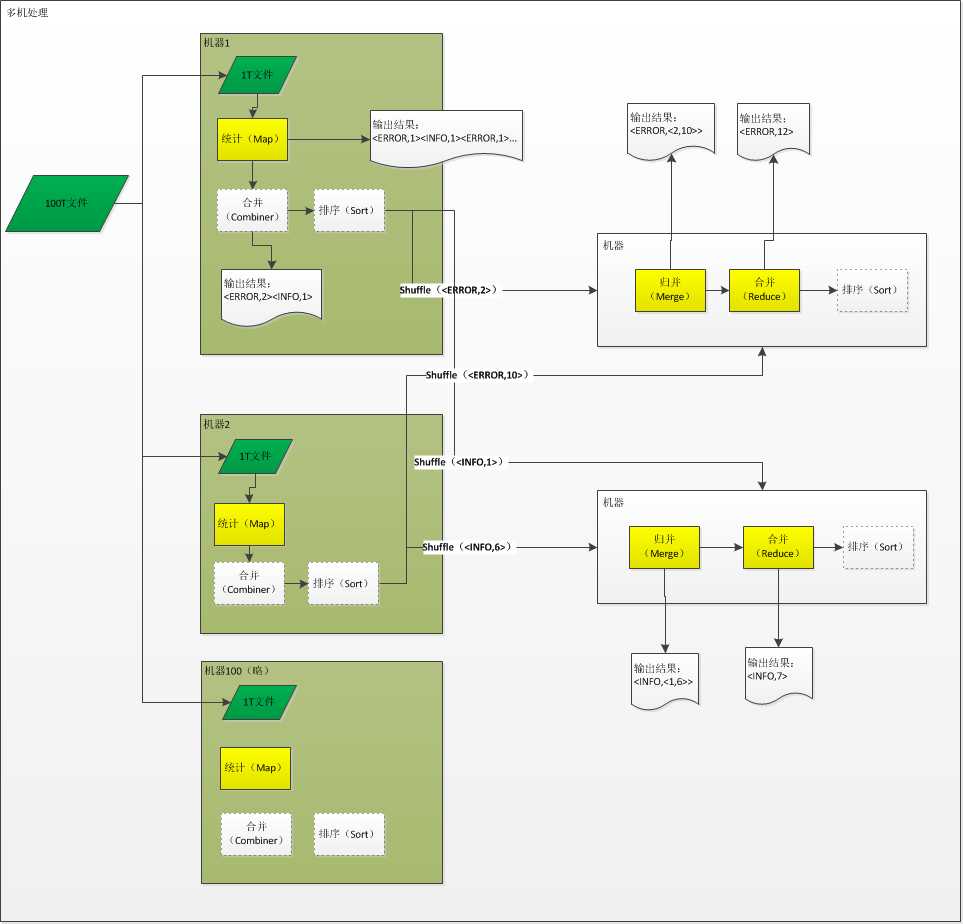
说明:
把100T文件分成100份,一台机器保存1T文件。
把程序代码复制100份,在100台机器上运行。
Combiner:对中间结果的合并,减少对带宽的占用,可以不使用,在reduce时统一合并。
Sort对于不需要顺序的程序里没意义(但MapReduce默认做了排序)。
Partitioner:将Map后的结果,分解为两部分(此例中只统计两个单词),准备送到两个Reduce任务,对于Reduce只有一个的时候没意义,如果有多个Reduce,则需要,可以继承Partitioner标准类,自己实现分解函数。
原文:http://www.cnblogs.com/liuxinan/p/5258182.html