Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
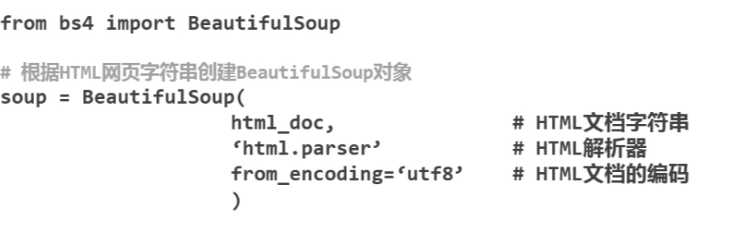

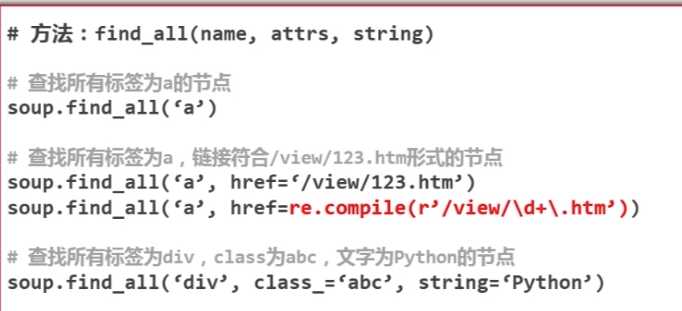
# -*- coding:utf-8 -*- #导入所需要的模块 from bs4 import BeautifulSoup import re #一段html的字符串 html_doc = """ <html><head><title>The Dormouse‘s story</title></head> <body> <p class="title"><b>The Dormouse‘s story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ #创建beautifulsoup对象 soup = BeautifulSoup(html_doc, ‘html.parser‘, from_encoding = ‘utf-8‘) #查找html文档中出现的所有链接 print ‘获取所有的链接:‘ links = soup.find_all(‘a‘) for link in links: print link.name, link[‘href‘], link.get_text() #查找html文档中lacie的链接 print ‘获取lacie的链接:‘ link_node = soup.find(‘a‘, href = ‘http://example.com/lacie‘) print link_node.name, link_node[‘href‘], link_node.get_text() #利用正则表达式进行模糊匹配 print ‘正则模糊匹配:‘ link_node = soup.find(‘a‘, href = re.compile(r"ill")) print link_node.name, link_node[‘href‘], link_node.get_text() #获取标题的文字 print ‘获取p段落文字:‘ link_node = soup.find(‘p‘, class_ = "title") print link_node.name, link_node.get_text()

本文为学习imooc笔记
原文:http://www.cnblogs.com/zpfcode/p/5184840.html