在通信协议中,经常碰到使用私有协议的场景,报文内容是肉眼无法直接看明白的二进制格式。由于协议的私有性质,即使大名鼎鼎的 Wireshark,要解析其内容,也无能为力。
面对这种情况,开发人员通常有两个办法:第一,对照报文内容和协议规范进行人工分析(假设内容没有经过加密、压缩);第二,编程实现协议报文的解析(源于程序员的懒惰 ^_^)。
很明显,第二条道路是主流。目前比较常见的实现方式是开发对应的 Wireshark 插件,包括 C、Lua 等插件。当然,插件完成后需要运行 Wireshark 才能调用插件进行协议解析,操作上相对厚重。
有没有更好的办法?自然我们会想到 Python,用脚本对二进制格式报文进行内容解析。这方面的资料,网上也有一大把。
到此,似乎问题就完结了。但是,仔细考虑,仍有提升的空间,一般而言,解析私有协议,往往是一种协议对应一个解析脚本。在只有少数几种协议需要解析的情况下,采用这种 ad hoc 的方式可以搞定,解析脚本甚至可以用完即丢。如果有很多种协议呢?比如说几十种,那怎么办?此时还用这种“一事一议”的方法未免就不太聪明了。
那么,能否开发一个通用的二进制格式协议解析脚本,使得理论上对于任意一种二进制格式的报文,都能够解析出来?
本篇给出一个 Python 编写的解析脚本,试图回答这个问题。
我们通过一个示例,演示如何使用此脚本。
假设有一个应用层协议 FOO,承载在 UDP 12345 端口上,协议内容是记录用户从 FTP 服务器下载或上传文件的信息。
将协议的一次交互过程抓包,得到文件 Foo.pcap,内容如下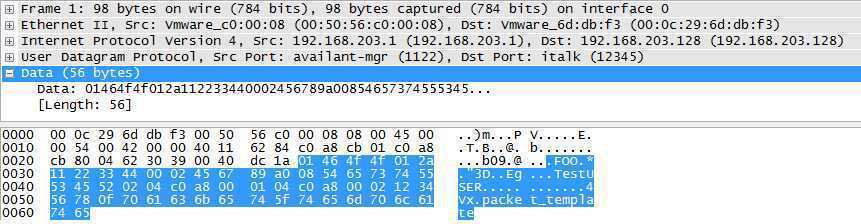
下面是 F00 协议规范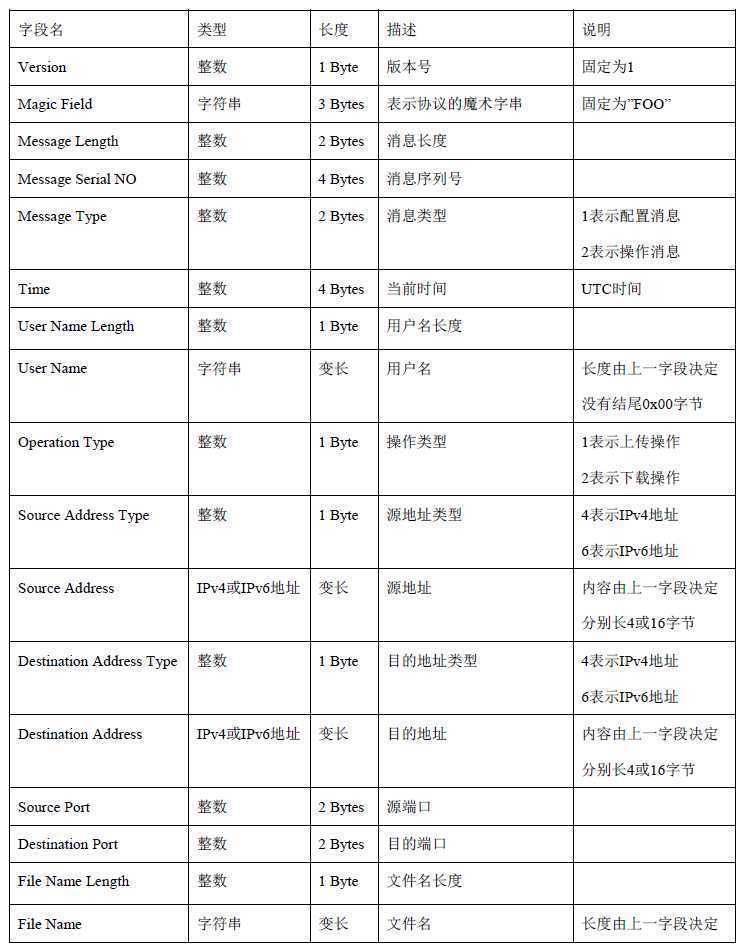
现在我们再准备一个模板文件 packet.template,该文件的基本内容已经提供好。只需要在文件中增加一个协议模板 FOO,协议模板的内容如下。
{FOO}
# 字段名 类型 长度 描述 取值约束
Version UINT8 1 版本号 (1)
MagicField CHAR[] 3 表示协议的魔术字串 FOO
MessageLength UINT16 2 消息长度
MessageSerialNO UINT32 4 消息序列号
MessageType UINT16 2 消息类型 (1-配置消息|2-操作消息)
Time TIME 4 当前时间 日志产生时间,用UTC时间表示
UserNameLength UINT8 1 用户名长度 N
UserName CHAR[] N 用户名
OperationType UINT8 1 操作类型 (1-上传|2-下载)
SourceAddressType UINT8 1 源地址类型 {4-4/IPV4 | 16-16/IPV6}
SourceAddress IPV4|IPV6 U 源地址
DestinationAddressType UINT8 1 目的地址类型 {4-4/IPV4 | 16-16/IPV6}
DestinationAddress IPV4|IPV6 U 目的地址
SourcePort UINT16 2 源端口
DestinationPort UINT16 2 目的端口
FileNameLength UINT8 1 文件名长度 N
FileName CHAR[] N 文件名
对比上图,可以发现,协议模板与协议规范,其字段是一一对应的,部分字段作了局部的微调。
要注意的是【长度】和【取值约束】。如何填写这两列,请参考模板文件中的说明。
都准备好后,在命令行运行:
D:\>c:\Python27\python.exe packet_parse_python2.py packet.template FOO.pcap
下面是部分解析结果输出
IPv4
版本 -- 4
包头长度 -- 5
Differentiated Services Codepoint -- 0
Explicit Congestion Notification -- 0
总长度 -- 84
标识 -- 66
标记 -- 0
分段偏移 -- 0
生存期 -- 64
协议 -- 17 UDP
报文头校验码 -- 0x6284
源地址 -- 192.168.203.1
目的地址 -- 192.168.203.128
UDP
源端口号 -- 1122
目标端口号 -- 12345 FOO
数据报长度 -- 64
校验值 -- 56346
FOO
版本号 -- 1
表示协议的魔术字串 -- FOO
消息长度 -- 298
消息序列号 -- 287454020
消息类型 -- 2 操作消息
当前时间 -- 2006-11-25 00:09:04
用户名长度 -- 8
用户名 -- TestUSER
操作类型 -- 2 下载
源地址类型 -- 4 4/IPV4
源地址 -- 192.168.0.1
目的地址类型 -- 4 4/IPV4
目的地址 -- 192.168.0.2
源端口 -- 4660
目的端口 -- 22136
文件名长度 -- 15
文件名 -- packet_template
……部分省略……
56 c0 00 08 08 00 45 00 - 00 54 00 42 00 00 40 11
| | | | | | | |
| | | | | | | 协议 -- 17
| | | | | | 生存期 -- 64
| | | | | 标记 -- 0 | 分段偏移 -- 0
| | | | 标识 -- 66
| | | 总长度 -- 84
| | Differentiated Services Codepoint -- 0 | Explicit Congestion Notification -- 0
| 版本 -- 4 | 包头长度 -- 5
上层协议 -- 0x0800
62 84 c0 a8 cb 01 c0 a8 - cb 80 04 62 30 39 00 40
| | | | | |
| | | | | 数据报长度 -- 64
| | | | 目标端口号 -- 12345
| | | 源端口号 -- 1122
| | 目的地址 -- 192.168.203.128
| 源地址 -- 192.168.203.1
报文头校验码 -- 0x6284
dc 1a 01 46 4f 4f 01 2a - 11 22 33 44 00 02 45 67
| | | | | | |
| | | | | | 当前时间 -- 2006-11-25 00:09:04
| | | | | 消息类型 -- 2
| | | | 消息序列号 -- 287454020
| | | 消息长度 -- 298
| | 表示协议的魔术字串 -- FOO
| 版本号 -- 1
校验值 -- 56346
89 a0 08 54 65 73 74 55 - 53 45 52 02 04 c0 a8 00
| | | | |
| | | | 源地址 -- 192.168.0.1
| | | 源地址类型 -- 4
| | 操作类型 -- 2
| 用户名 -- TestUSER
用户名长度 -- 8
01 04 c0 a8 00 02 12 34 - 56 78 0f 70 61 63 6b 65
| | | | | |
| | | | | 文件名 -- packet_template
| | | | 文件名长度 -- 15
| | | 目的端口 -- 22136
| | 源端口 -- 4660
| 目的地址 -- 192.168.0.2
目的地址类型 -- 4
74 5f 74 65 6d 70 6c 61 - 74 65
设计思路:代码不变,数据驱动。原则上只需要扩充协议模板。
解析的应用层协议,其字段之间暂不支持类似 ASN1 语法的 TLV 嵌套形式。
部分 BUG 遗留,需要完善,欢迎反馈。
最后,附上
解析脚本(Python 2.X)packet_parse_python2.py

# coding=gbk # 需要 bitstring-2.1.1 和 win_inet_pton-1.0.1 支持 # first # cd <Python2x目录>\Lib\bitstring-2.1.1 # python setup.py install # second # cd <Python2x目录>\Lib\win_inet_pton-1.0.1 # python setup.py install from bitstring import BitStream import sys import re import time import win_inet_pton import socket import struct # 字段名 类型 长度 中文描述 取值约束 class TemplateEntry(object): def __init__(self, field): self.fieldName = field[0] self.fieldType = field[1] self.fieldLen = field[2] self.fieldChDesc = field[3] self.fieldRestri = field[4] class ParseTemplate(object): def __init__(self, templateName): self.name = templateName self.arrayTemplate = [] if len(sys.argv) < 3: print "使用方法:", sys.argv[0], ‘[-d] 解析模板 待解析文件‘ print "说 明: -d 为可选参数,表示打开调试开关" exit() matchedTuples = [] currentBitPosition = 0 lastReadBits = 0 templateFile = sys.argv[1] dataFile = sys.argv[2] debug = 0 if sys.argv[1] == ‘-d‘: debug = 1 templateFile = sys.argv[2] dataFile = sys.argv[3] template_list = []; print ‘解析模板文件‘, templateFile, ‘...‘ try: template_file = open(templateFile, ‘r‘) except IOError: print "文件", templateFile, ‘打开失败‘ exit() all_lines = template_file.readlines(); template_file.close(); for each_line in all_lines: if not re.match(‘#‘, each_line): try: each_line = each_line.strip(‘\n‘); # 去掉末尾换行 # print ‘\n‘, r‘trim \n -> [‘+each_line+‘]‘ if re.match(‘{‘, each_line): match = re.search(r‘{(.*)}‘, each_line) TemplateName = match.group(1) myTemplate = ParseTemplate(TemplateName) if debug: print ‘结构名:‘, myTemplate.name template_list.append(myTemplate) else: field_split = each_line.split("\t") # \t 分割字段, 例如 ‘A\t\t\tB\t\tC\t\tD\tE‘ 得到 # ‘A‘, ‘‘, ‘‘, ‘B‘, ‘‘, ‘C‘, ‘‘, ‘D‘, ‘E‘ # print r‘split \t ->‘ , field_split while ‘‘ in field_split: # 去掉分割得到的多个空串 field_split.remove(‘‘) if len(field_split) == 0: # print ‘空列表‘ continue # print r"remove ‘‘ ->" , field_split while len(field_split) != 5: # 补足长度 field_split.append(‘‘) curEntry = TemplateEntry(field_split) myTemplate.arrayTemplate.append(curEntry) except ValueError: pass print ‘\n打开数据文件‘, dataFile, ‘...‘ try: data_file = open(dataFile, ‘rb‘) except IOError: print "文件", dataFile, ‘打开失败‘ exit() whole_content = data_file.read() # print whole_content if debug: # 16 字节一行显示: xx xx xx xx xx xx xx xx -- xx xx xx xx xx xx xx xx lines = [whole_content[i:i+8] for i in range(0, len(whole_content), 8)] line_count = 0 for line in lines: if line_count %2 == 1: print ‘-‘, ‘ ‘.join("{0:02x}".format(ord(x)) for x in line) else: print ‘ ‘.join("{0:02x}".format(ord(x)) for x in line), line_count += 1 print b = BitStream(bytes=whole_content) if debug: for template in template_list: print ‘template:‘, template.name for element in template.arrayTemplate: print " <%s> <%s> <%s> <%s> <%s>" % (element.fieldName, element.fieldType, element.fieldLen, element.fieldChDesc, element.fieldRestri) def matchTuples(index, parseTuples): tempResult = ‘‘ for parseTuple in parseTuples: if index == parseTuple[0]: # 同一个 parseIndex 有可能对应多个字段 if len(tempResult) == 0: tempResult = parseTuple[1] else: tempResult = tempResult + ‘ | ‘ + parseTuple[1] if len(tempResult) == 0: return None else: return tempResult # parseString def displayParseLine(line, displayTuples): displayOneLineList = [] count = 0 start = 16*(line - 1) end = 16*line for i in range(start, end, 1): # 收集一行内待显示竖线的位置信息 parseString = matchTuples(i, displayTuples) if parseString: count += 1 displayOneLineList.append((i, parseString)) displayOneLineList.append((0, ‘‘)) # XX XX XX XX XX XX XX XX - XX XX XX XX XX XX XX XX -- 一行 16 进制字符 # 0 3 6 9 12 15 18 21 26 29 32 35 38 41 44 47 -- verticalIndexRange # 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 -- x verticalIndexRange = range(0,22,3) + range(26,48,3) lastWidth = 0 # 上一行输出宽度 for verticalCount in range(count,0,-1): # (count, count-1 ... 1) i = 0 j = 0 # 当前行输出多少个字符 for verticalIndex in range(49): # 48 -- 行内最大坐标 if verticalIndex in verticalIndexRange: x = verticalIndexRange.index(verticalIndex) if matchTuples(start+x, displayTuples): sys.stdout.write(‘|‘) i += 1 j += 1 if i >= verticalCount: break else: sys.stdout.write(‘ ‘) # print ‘ ‘, j += 1 else: sys.stdout.write(‘ ‘) # print ‘ ‘, j += 1 if lastWidth > j: sys.stdout.write(‘ ‘*(lastWidth-j-1)) print displayOneLineList[-(count-verticalCount+1)][1] elif lastWidth == 0: # 第一次循环,特别对待 print lastWidth = j sys.stdout.write(‘ ‘*(lastWidth-1)) print displayOneLineList[0][1] def displayParse(text, displayTuples): # 16 字节一行显示: xx xx xx xx xx xx xx xx -- xx xx xx xx xx xx xx xx lines = [text[i:i+8] for i in range(0, len(text), 8)] line_count = 0 for line in lines: if line_count%2 == 1: print ‘-‘, ‘ ‘.join("{0:02x}".format(ord(x)) for x in line) else: print print ‘ ‘.join("{0:02x}".format(ord(x)) for x in line), line_count += 1 if line_count%2 == 0: displayParseLine(line_count/2, displayTuples) # 根据类型和长度确定 bitstring:read 的读入参数 def valueFromTypeAndLen(b, fieldType, fieldLen): ‘‘‘ 输入格式 UINT8 1 UINT16 2 UINT16LE 2 UINT32 4 HEX[] 4 IPV4 4 CHAR[] 10 IPV6 16 CHAR[] N IPV4|IPV6 U {XXXX} 1 ‘‘‘ global currentBitPosition, lastReadBits data = ‘‘ length = int(fieldLen); if length == 0: return data try: # fieldLen > 1 只考虑少数情况 if fieldType == "UINT8": data = b.read(‘uint:8‘) currentBitPosition += 8 lastReadBits = 8 elif fieldType == "UINT16": data = b.read(‘uint:16‘) currentBitPosition += 16 lastReadBits = 16 elif fieldType == "UINT16LE": data = b.read(‘uintle:16‘) currentBitPosition += 16 lastReadBits = 16 elif fieldType == "UINT16BE": data = b.read(‘uintbe:16‘) currentBitPosition += 16 lastReadBits = 16 elif fieldType == "UINT32": data = b.read(‘uint:32‘) currentBitPosition += 32 lastReadBits = 32 elif fieldType == "UINT32LE": data = b.read(‘uintle:32‘) currentBitPosition += 32 lastReadBits = 32 elif fieldType == "UINT32BE": data = b.read(‘uintbe:32‘) currentBitPosition += 32 lastReadBits = 32 elif fieldType == "UINT64": data = b.read(‘uint:64‘) currentBitPosition += 64 lastReadBits = 64 elif fieldType == "TIME": data = b.read(‘uint:32‘) data = time.strftime("%Y-%m-%d %X", time.gmtime(int(data))) # 转成 UTC 时间 currentBitPosition += 32 lastReadBits = 32 elif fieldType == "TIME_LE": data = b.read(‘uintle:32‘) data = time.strftime("%Y-%m-%d %X", time.gmtime(int(data))) # 转成 UTC 时间 currentBitPosition += 32 lastReadBits = 32 elif fieldType == "HEX[]": length = 8*length formatString = ‘hex:‘ + str(length) data = b.read(formatString) currentBitPosition += length lastReadBits = length elif fieldType == "MAC[]": length = 8*length formatString = ‘hex:‘ + str(length) data = b.read(formatString) data = data.lstrip(‘0x‘) data = [data[i:i+2] for i in range(0, len(data), 2)] data = ‘:‘.join(data) currentBitPosition += length lastReadBits = length elif fieldType == "IPV4": data = b.read(‘uint:32‘) data = socket.inet_ntoa(struct.pack(‘!L‘, data)) currentBitPosition += 32 lastReadBits = 32 elif fieldType == "IPV6": formatString = ‘bytes:16‘ data = b.read(formatString) data = socket.inet_ntop(socket.AF_INET6, data) currentBitPosition += 128 lastReadBits = 128 elif fieldType == "CHAR[]": formatString = ‘bytes:‘ + str(length) data = b.read(formatString) data = data.strip(‘\0‘) currentBitPosition += 8*length lastReadBits = 8*length elif fieldType == "BIT[]": data = b.read(length).uint currentBitPosition += length lastReadBits = length except: print "Reading ERROR" displayParse(whole_content, matchedTuples) exit() else: pass return data # 将输入参数转成整数并返回结果 # 目前只考虑输入参数是字符串和整数两种情况 def value2int(value): if type(value) == type(‘‘): # 字符串 if value.startswith(‘0x‘) or value.startswith(‘0X‘): return int(value, 16) else: return int(value) return value # 如果本身已经是整数,则返回整数自身 # 查找 index 是否在 searchString 的数字索引中,根据 mode 的不同表现不同 # mode searchString index # 1 ()中的内容: (0xd4c3b2a1) or (4-IPV4|16-IPV6) 必须为 0xd4c3b2a1 或 4 或 16,否则出错 # 2 []中的内容: [0-enlish | 1-中文] 可以为 0、1 或者其他 # 3 {}中的内容: {4-4/IPV4 | 16-16/IPV6} 必须为 4 或 16,并且‘-‘后跟内容,否则出错 def indexMatchList(index, searchString, mode): origin_index = index index = value2int(index) array = searchString.split(‘|‘) for entry in array: match_tuples = re.search(r‘\s*([^-]+)-([^-]*)\s*‘, entry) # 提取 id-name 对 match_digtal = re.search(r‘\s*((0x|0X)?[\da-fA-F]+)\s*‘, entry) # 提取 (1|2|3) 中的单个数字 if match_tuples != None: # id-<null> 或 id-xxx id = match_tuples.group(1) id = id.strip() id = value2int(id) name = match_tuples.group(2) name = name.strip() if index == id: if len(name) == 0 and mode == 3: print ‘NOT Allowed -- only type no union struct‘ exit() else: return name elif match_digtal != None: # only id id = match_digtal.group(1) id = id.strip() id = value2int(id) if index == id: if mode == 3: print ‘NOT Allowed -- only type no union struct‘ exit() else: return True if mode == 1 or mode == 3: # 没找到 id print ‘<%s> NOT in <%s>‘ % (origin_index, searchString) exit() else: return ‘<<other>>‘ # 在 < 1-xxx | 2-yyy | 3-zzz | ... > 中查找数字索引对应的名字 # 比如 1 对应 xxx, 2 对应 yyy def indexToString(index, searchString): index = value2int(index) array = searchString.split(‘|‘) for entry in array: match_tuples = re.search(r‘\s*([^-]+)-([^-]+)\s*‘, entry) # 提取 <id,name> 对 if match_tuples != None: id = match_tuples.group(1) name = match_tuples.group(2) name = name.strip() id = id.strip() id = value2int(id) if index == id: return name return None # 根据名字查找模板 def findTemplate(templateName, templateList): for template in templateList: if templateName == template.name: return template return None # 报文解析 def parseBinary(bitStream, templateName, templateList): global matchedTuples curTemplate = findTemplate(templateName, templateList) if curTemplate == None: print "\n没找到模板", templateName exit() print templateName lastAction = 0 isUnion = 0 lastLength = None for element in curTemplate.arrayTemplate: (fieldName, fieldType, fieldLen, fieldChDesc, fieldRestri) = (element.fieldName, element.fieldType, element.fieldLen, element.fieldChDesc, element.fieldRestri) if debug: print "<%s> <%s> <%s> <%s> <%s>" % (fieldName, fieldType, fieldLen, fieldChDesc, fieldRestri) if fieldLen == ‘U‘ and ‘|‘ in fieldType: # 针对 (长度, 类型)==(‘U‘, ‘XXX|YYY|ZZZ‘) 格式进行修正 if isUnion: # 前面是否设置了 union 标记 (fieldLen, fieldType) = unionFormat.split(‘/‘) fieldLen = fieldLen.strip() fieldType = fieldType.strip() isUnion = 0 elif fieldLen == ‘N‘: if lastLength != None: # lastLength 可能在处理上一字段时被赋值为 0 fieldLen = lastLength lastLength = None if fieldType.startswith(‘{‘): # 结构字段 match = re.search(r‘{(.*)}‘, fieldType) # 从 fieldType 中提取结构名 curTemplateName = match.group(1) if fieldLen == ‘X‘: while 1: print ‘\n================================================================================‘ parseBinary(bitStream, curTemplateName, templateList) else: parseBinary(bitStream, curTemplateName, templateList) else: # 普通字段 fieldValue = valueFromTypeAndLen(bitStream, fieldType, fieldLen) print ‘ ‘, fieldChDesc, ‘--‘, fieldValue, parseIndex = (currentBitPosition - lastReadBits)/8 parseString = fieldChDesc + ‘ -- ‘ + str(fieldValue) # 对说明字段进行判断 match_angle_bracket = re.search(r‘<(.*)>‘, fieldRestri) # 包含 <> 表示后面跟若干个结构 match_parenthese = re.search(r‘\((.*)\)‘, fieldRestri) # 包含 () 表示取值必须在()范围中 match_square_bracket = re.search(r‘\[(.*)\]‘, fieldRestri) # 包含 [] 表示取值可以在、也可以不在[]范围内 match_brace = re.search(r‘{(.*)}‘, fieldRestri) # 包含 {} 表示下一字段类型由当前字段值决定 if fieldRestri == ‘N‘: lastLength = int(fieldValue) print elif match_angle_bracket != None: # <1-Ethernet | 20-IEEE_802_11> or <1-TCP|17-UDP> curRestriction = match_angle_bracket.group(1) name = indexToString(fieldValue, curRestriction) if name != None: lastAction = 1 lastTemplate = name print name else: print ‘NOT found template: value = <%s>, searchstring = <%s>‘ % (fieldValue, curRestriction) exit() elif match_parenthese != None: # (0xd4c3b2a1) or (4-IPV4 | 16-IPV6) curRestriction = match_parenthese.group(1) ret = indexMatchList(fieldValue, curRestriction, 1) if ret != True: print ret else: print elif match_square_bracket != None: # [0-enlish | 1-中文] curRestriction = match_square_bracket.group(1) ret = indexMatchList(fieldValue, curRestriction, 2) if ret != True: print ret else: print elif match_brace != None: # {4-4/IPV4 | 16-16/IPV6} curRestriction = match_brace.group(1) ret = indexMatchList(fieldValue, curRestriction, 3) print ret isUnion = 1 unionFormat = ret else: print matchedTuples.append((parseIndex, parseString)) if lastAction: print if debug: print ‘searching template <%s> int the END‘ % lastTemplate parseBinary(bitStream, lastTemplate, templateList) parseBinary(b, "pcap_file_header", template_list)
模板文件 packet.template
# 字段名 类型 长度 描述 取值约束
#
# 格式要求:【字段名】【类型】【长度】【描述】【取值约束】字段之间使用 TAB 键分隔
#
# 【长度】字段说明:
# 数字 固定长度
# N 由上一字段决定: 即当前字段的长度由上一字段值决定
# S 当前字段为结构体,由所在行的类型字段决定
# U 当前字段类型由上一字段决定, union
#
# 【取值约束】字段说明:
# []表示解析的字段值可以在范围内, 也可以不在范围内, 如果在范围中,则字段值有明确的含义,否则表示不定
# 比如 [1-ftp | 2-http | 3-dns] 表示:1为FTP, 2为HTTP, 3为DNS,如果是其他数字,则表示other
#
# ()表示解析的字段值必须在()范围中
# 比如 (4-IPV4 | 16-IPV6)表示 字段值只能等于4或6
#
# <>除了与()一样外,<>中的数字还表示模板,比如<0x0800-IPv4>和<1-TCP|17-UDP>
# 之所以用符号<>,因为类似 HTML 中的链接 <a href>
#
# {} 表示下一字段类型由当前字段值决定,类似 C 语言中的 type-union 结构
# 比如 {4-4/IPV4 | 16-16/IPV6} 表示,如果当前字段值是4,则下一字段为IPV4地址,如果是6,则为IPV6地址
# 斜杠/将左右分为 长度/类型
#
# N 如果是 N,表示下一字段的长度由当前值决定,当前字段与下一字段类似 Len/Value 的关系
#
# <include general.template> -- 可以考虑将通用的协议描述(比如 IP/TCP/UDP )放在一个单独的模板文件里
{pcap_file_header}
# 字段名 类型 长度 描述 取值约束
pcap_magic HEX[] 4 pcap文件标识 {0xd4c3b2a1-S/{header_info_little} | 0xa1b2c3d4-S/{header_info_big}}
header_info {header_info_little}|{header_info_big} U pcap文件头信息 pcap_magic字段决定后续字段是大端、还是小端
{header_info_big}
# 字段名 类型 长度 描述 取值约束
version_major UINT16BE 2 主版本号 #define PCAP_VERSION_MAJOR 2
version_minor UINT16BE 2 次版本号 #define PCAP_VERSION_MINOR 4
thiszone UINT32BE 4 时区
sigfigs UINT32BE 4 精确时间戳
snaplen UINT32BE 4 抓包最大长度
linktype UINT32BE 4 链路类型 <1-EthernetS | 20-IEEE_802_11S>
{header_info_little}
# 字段名 类型 长度 描述 取值约束
version_major UINT16LE 2 主版本号 #define PCAP_VERSION_MAJOR 2
version_minor UINT16LE 2 次版本号 #define PCAP_VERSION_MINOR 4
thiszone UINT32LE 4 时区
sigfigs UINT32LE 4 精确时间戳
snaplen UINT32LE 4 抓包最大长度
linktype UINT32LE 4 链路类型 <1-EthernetS | 20-IEEE_802_11S>
{EthernetS}
# pcap 的特殊结构: 抓包个数事先未知, 读文件要无限循环
# 字段名 类型 长度 描述 取值约束
packet_header {Ethernet} X 数据结构数组 X表示无限个元素
{pcap_packet_header}
# 字段名 类型 长度 描述 取值约束
tv_sec TIME_LE 4 抓包时间(当作小端序) 1970/1/1零点开始以来的秒数
tv_usec UINT32LE 4 毫秒数(当作小端序) 当前秒之后的毫秒数
caplen UINT32LE 4 抓包长度(当作小端序)
len UINT32LE 4 实际长度(当作小端序)
{Ethernet}
# 字段名 类型 长度 描述 取值约束
packet_header {pcap_packet_header} S 数据包头 通用包头
ether_dhost MAC[] 6 目的MAC地址
ether_shost MAC[] 6 源MAC地址
ether_type HEX[] 2 上层协议 <0x0800-IPv4>
{IPv4}
# 字段名 类型 长度 描述 取值约束
Version BIT[] 4 版本 (4) 表示当前为 IPv4 版本
IHL BIT[] 4 包头长度 以32位为单位,最小值为5
DSCP BIT[] 6 Differentiated Services Codepoint
ECN BIT[] 2 Explicit Congestion Notification
Total Length UINT16 2 总长度 IP数据包的总长度,包括包头和后跟的数据
Identification UINT16 2 标识 识别报文,用于分段重组
Flags BIT[] 3 标记 分为 保留|DF|MF 共3位
Fragment Offset BIT[] 13 分段偏移 当前段在整个数据报中的偏移--以64位为单位
Time To Live UINT8 1 生存期 报文在internet中的生存时间。如果为零,则丢弃
Protocol UINT8 1 协议 <1-TCP|17-UDP>
Header Checksum HEX[] 2 报文头校验码
Source IP IPV4 4 源地址
Destination IP IPV4 4 目的地址
{TCP}
{UDP}
# 字段名 类型 长度 描述 取值约束
Source port UINT16 2 源端口号
Destination port UINT16 2 目标端口号 <12345-FOO>
Length UINT16 2 数据报长度
Checksum UINT16 2 校验值
{FOO}
# 字段名 类型 长度 描述 取值约束
Version UINT8 1 版本号 (1)
MagicField CHAR[] 3 表示协议的魔术字串 FOO
MessageLength UINT16 2 消息长度
MessageSerialNO UINT32 4 消息序列号
MessageType UINT16 2 消息类型 (1-配置消息|2-操作消息)
Time TIME 4 当前时间 日志产生时间,用UTC时间表示
UserNameLength UINT8 1 用户名长度 N
UserName CHAR[] N 用户名
OperationType UINT8 1 操作类型 (1-上传|2-下载)
SourceAddressType UINT8 1 源地址类型 {4-4/IPV4 | 16-16/IPV6}
SourceAddress IPV4|IPV6 U 源地址
DestinationAddressType UINT8 1 目的地址类型 {4-4/IPV4 | 16-16/IPV6}
DestinationAddress IPV4|IPV6 U 目的地址
SourcePort UINT16 2 源端口
DestinationPort UINT16 2 目的端口
FileNameLength UINT8 1 文件名长度 N
FileName CHAR[] N 文件名
原文:http://www.cnblogs.com/efzju/p/5115232.html
