参考文件:https://docs.nvidia.com/cuda/cuda-c-programming-guide/
1. GPU介绍
1.1 根据文档说明,一开始GPU是因为市场上的CPU已经不能满足real-time的3D图像显示带来的巨大计算量,经过这么多年的发展,GPU已经成了并行运算的基石。GPU相比于CPU有这些优势:高并行(high-parallel),多线程(multithreaded),大存储带宽(high memory bandwidth)。大家可以去看最早的CPU之一的8086处理器,这些处理器的处理过程就是不断从内存中取指令,执行指令,是不能够并行的,多线程由程序上下文的切换和时间碎片分配实现的,而GPU则可以在硬件上运行多个线程,这和CPU的多核也是一样的道理。这里附上Nvida的显卡浮点计算的比较图表。
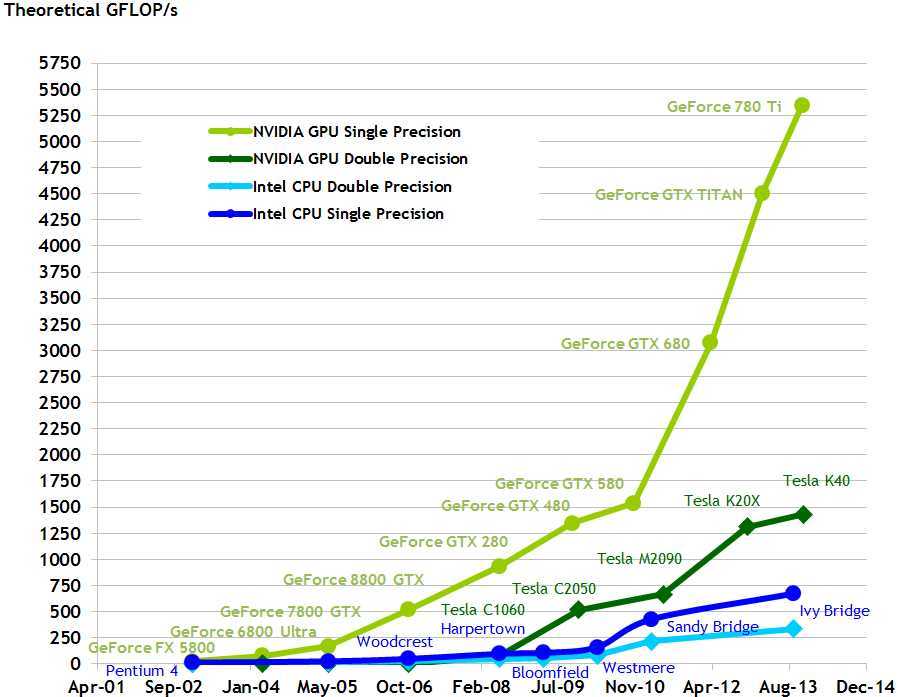
可以看出GPU的计算能力也是比较符合摩尔定律的,计算能力的增长十分迅速(当然,这是Nvida的文档,在这里就要体现出该公司产品的牛逼之处了,Geforece的浮点计算能力相比与其他CPU要快很多),这里值得一提的是,目前世界上最快的超级计算机--天河二号就是基于Ivy Bridge搭建的。
下面的是内存带宽的图标(大家可能不是很理解内存带宽的意思,这里简单解释一下,我们都知道CPU都有总线的带宽,比如80386的总线带宽就是20位,这里的内存带宽表示的是同时能够供各个核心使用的内存的大小)
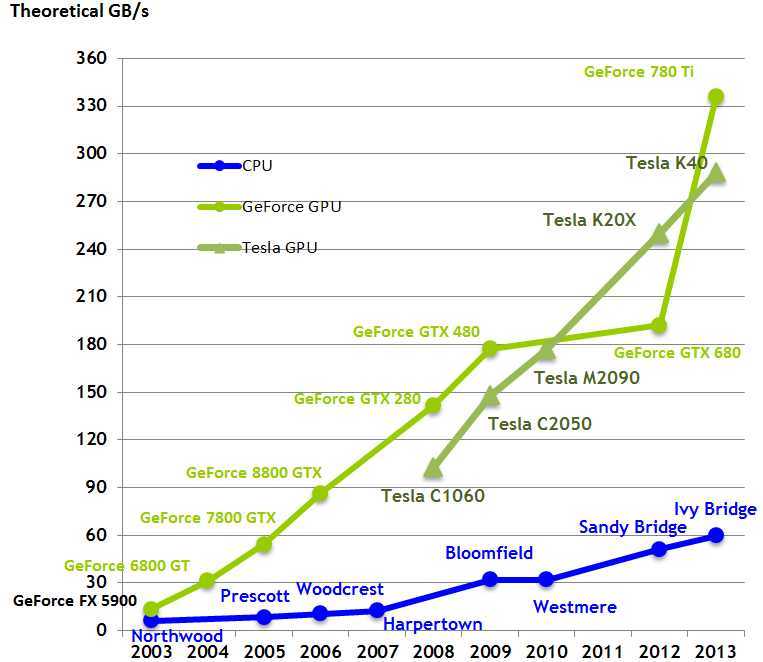
GPU之所以能够在计算能力上秒杀CPU,主要是因为它是计算密集的,高并行的计算模型(非常适合图像的渲染),其中大部分的单元用于数据处理而不是像CPU那样存在很多数据读取和存入和流量控制,如下图所示:
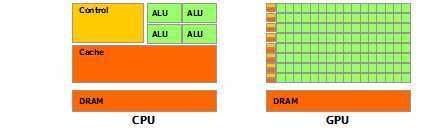
从上图可以看出,CPU的主要核心部件的功能并不是用于数据运算,而是一个公用计算核心的一个系统,从Control,Cache就可以看出流程控制和数据寄存占了CPU很大的一部分,而GPU的数据处理更像是网格式的计算,这在数据量很大的矩阵运算中非常便利迅速。GPU有这么多优点,当然也存在一些缺点,首先,GPU没有CPU那样复杂的流程控制单元,所以可能在编程方式上和以往的传统变成有很大的不同。
1.2 CUDA 并行编程模型
CUDA是由NVIDA公司在2006年提出的用于在GPU上运行的程序的编程模型,CUDA也是一个编程环境,编程人员可以使用C语言进行CUDA程序的开发。当然,CUDA还提供了其他的编程语言接口,比如FORTRAN等。

上图就是CUDA的一个架构图,我们可以看出,CUDA提供了C,C++,FORTRAN,Java,Python等目前主流的编程语言,Libraries我们可以看作是GPU的驱动。这些驱动直接和NVIDA的GPU交互。
CUDA编程模型的设计一方面需要考虑到随着GPU的迅猛发展,以后的兼容性问题,另一方面,还考虑的编程人员从传统编程向并行变成模式的转换,CUDA C编程接口尽可能地和传统的C语言编程习惯靠拢(英文原文:The CUDA parallel programming model is designed to overcome this challenge while maintaining a low learning curve for programmers familiar with standard programming languages such as C.),后面会有详细的介绍。
CUDA模型的核心有三个方面:线程组层次结构(hierarchy of thread groups),共享内存(shared memories),障碍同步(暂时还想不到好的翻译,barrier synchronization)。这三个核心部分为数据和线程的并行提供了很好的基础,我们在并行编程中将一个大的Task分成很多粗粒的sub-task,这些sub-task需要能够独立在核心上完成运算(不需要其他的sub-task),其实CUDA只是提供了一个多线程的编程模型,是硬件无关的,例如说如果将来的GPU发展可能越来越多核,CUDA仍然适用,无需改变。(文档中使用了Automatic Scalability,就是自动扩展的)。
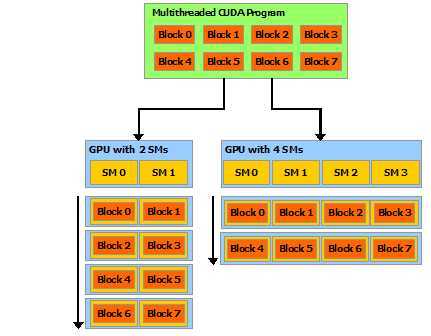
上图非常清楚地阐述了Automatic Scalability一词的意思,一个程序被分割成了8个block,可以在不同的硬件环境下适用,如果该程序在有两个Streaming Microprecessor的GPU上,那么该程序会将8个block分成两部分,每个SM处理四个block,同理如果GPU有4个SM,那个一个SM可能分配两个block。
2. CUDA编程模型详解
2.1 内核(Kernel)
这里的kernel可以理解为C中的function,是一个无状态的运算核心,可以被不同的线程调用(说的好像很高大上一样,其实就是一个function),kernel的定义需要使用__global_关键字,该kernel在调用的时候使用<<<...>>>来规定该kernel在多少个CUDA的线程中执行,也就是前面说的,把一个大的程序换分成小的block,分别在不同的核心上执行。下面贴上一个demo计算两个数组之和。
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
N表示N个线程运行这个kernel。
2.2 线程层次结构
这里要先介绍一下threadIdx, threadIdx是一个有着三个部分的vector,所以thread就可以在三维index上进行定位,举个例子,对于一维的Index,就和我们一般的寻址一样,thread[i]表示的就是第i个thread;二维的index,比如(D1,D2)那么该thread的index就是(D1+D2*y),y表示的是第二维的深度,以此类推。附上原文(以免自己说的不是很明白:))
The index of a thread and its thread ID relate to each other in a straightforward way: For a one-dimensional block, they are the same; for a two-dimensional block of size (Dx, Dy),the thread ID of a thread of index (x, y) is (x + y Dx); for a three-dimensional block of size (Dx, Dy, Dz ), the thread ID of a thread of index (x, y, z) is (x + y Dx + z Dx Dy).
下面是一个代码的例子:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
上面的代码是将两个矩阵相加存入另一个矩阵中,如果在我们传统的编程中,可能就是用两个for循环进行遍历,一个元素一个元素地相加,即使运行的机器再快,我们依然需要O(n^2)的时间,而GPU上矩阵的相加却不同,只需将A和B两个矩阵分别传送到GPU的内存中,然后直接使用运算单元一次性运算完成,运算复杂度为O(1)
这里还需要另外说明,一个block分配的线程数并不是不限制的,比如你用天河二号来计算,那么一个block不可能分配到几万个线程中(天河二号有16000个节点,一个节点有两个以上的处理器核心),并且,因为一个block需要共享内存,因此最好一个block只在一个处理器核上运算,CUDA限制最多的分配线程数是1024。
下图为blocks的线程分配图,从中我们可以看出,一个block可以分配到多个线程中进行执行,这些线程之间共享内存。
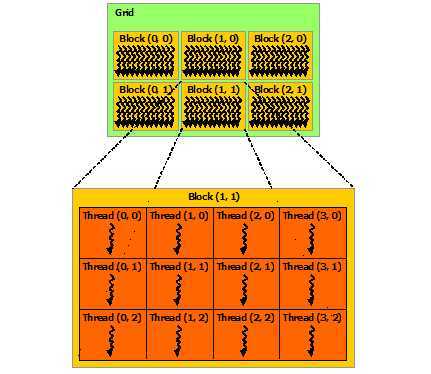
每个block分配的线程数以及每个grid的block数在<<<...>>>中指定(具体见上一段代码示例),上图的是二维的blocks,block可有kernel中的内置变量blockDim和blockInd定位,比如Block(1,1),下面的代码展示了如何handle multiple blocks
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
上面代码中threadPerBlock表示一个block里面有16×16(256)个thread,numBlocks表示一个grid里面的block数,因为多线程的执行顺序是不可知的,所以block的thread必须能够独立执行(不能和其他block的thread有任何联系),同一个block的thread可以互相交互(如共享内存),一说到共享内存,大家就会想起同步,锁等机制,在CUDA中有一个非常重要的概念就是synchronize point,一个thread设置了一个同步点,那么所有其他thread必须等待执行到该同步点,才能够继续执行程序,非常像进程通信中的锁机制,CUDA中通过调用kernel的__syncthreads()函数设置同步点。
为了共享内存的高效性,共享内存需要在各个处理器核心附近满足低潜伏期的特性(low-latency ),就像L1 Cache一样,这里低潜伏期我的理解是,尽量减少等待,多读写。
2.3 内存层次结构
CUDA中thread有可能在多个内存空间中读取数据,每个thread拥有自己私有的local memory,每个thread block具有共享内存,共享内存对于block中所有thread可见。
另外还有两个只读内存空间供所有thread访问,常量区和TeX true内存空间(由于这方面比较复杂,所以具体机制会在后续的博客中说明),下面图很好的展示了CUDA大致的内存结构
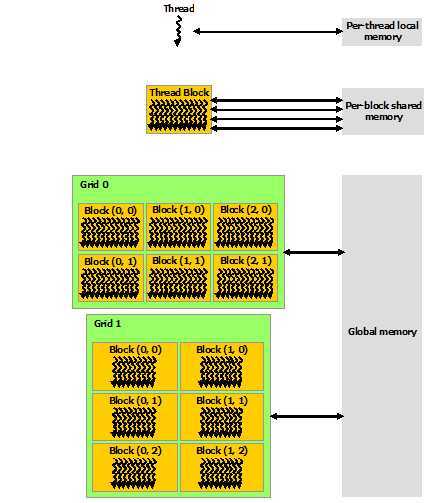
2.4 异构编程
CUDA是一种异构编程架构,正如前面介绍的那样,每个kernel分成blocks在GPU上运行,作为在CPU上运行的host程序的coprocessor,所以,虚拟化来说,每个kernel运行就像是在host上挂载了一个新的处理器核心。我们称主程序为host,每个kernel运行为device,host和每个device都维护自己的主存,因此,之前提到的全局内存,TeX true等都是kernel从host中获取的资源,其初始化也包括了device memory的allocation和deallocation.
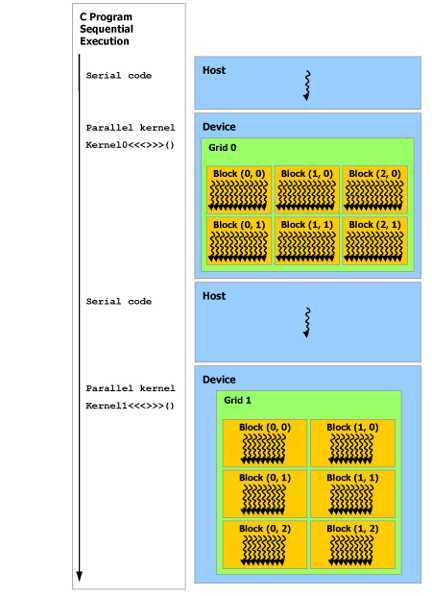
host在主线程上运行的同时,多个并行kernel在GPU上运行。
到这里就写了前两章,后面的会尽快补上。本人菜鸟,有错误还望大神指出。
原文:http://www.cnblogs.com/RookieCoder/p/5036306.html