val input=sc.textFile(inputFileDir)
val lines =sc.parallelize(List("hello world","this is a test"));
val lines =sc.parallelize(List("error:a","error:b","error:c","test"));
val errors=lines.filter(line => line.contains("error"));
errors.collect().foreach(println);
val lines =sc.parallelize(List("error:a","error:b","error:c","test","warnings:a"));
val errors=lines.filter(line => line.contains("error"));
val warnings =lines.filter(line => line.contains("warnings"));
val unionLines =errors.union(warnings);
unionLines.collect().foreach(println);
/**程序示例:接上
* Take the first num elements of the RDD. This currently scans the partitions *one by one*, so
* it will be slow if a lot of partitions are required. In that case, use collect() to get the
* whole RDD instead.
*/
def take(num: Int): JList[T]
unionLines.take(2).foreach(println);
val all =unionLines.collect();
all.foreach(println);
class searchFunctions (val query:String){
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchFunctionReference(rdd: RDD[String]) :RDD[String]={
//问题: isMach表示 this.isMatch ,因此我们需要传递整个this
rdd.filter(isMatch)
}
def getMatchesFunctionReference(rdd: RDD[String]) :RDD[String] ={
//问题: query表示 this.query ,因此我们需要传递整个this
rdd.flatMap(line => line.split(query))
}
def getMatchesNoReference(rdd:RDD[String]):RDD[String] ={
//安全,只把我们需要的字段拿出来放入局部变量之中
val query1=this.query;
rdd.flatMap(x =>x.split(query1)
)
}
}
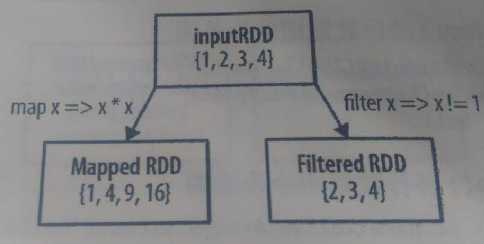
val rdd=sc.parallelize(List(1,2,3,4));
val result=rdd.map(value => value*value);
println(result.collect().mkString(","));
val rdd=sc.parallelize(List(1,2,3,4));
val result=rdd.filter(value => value!=1);
println(result.collect().mkString(","));
def filterFunction(value:Int):Boolean ={
value!=1
}
val rdd=sc.parallelize(List(1,2,3,4));
val result=rdd.filter(filterFunction);
println(result.collect().mkString(","));
val rdd=sc.parallelize(List("Hello world","hello you","world i love you"));
val result=rdd.flatMap(line => line.split(" "));
println(result.collect().mkString("\n"));
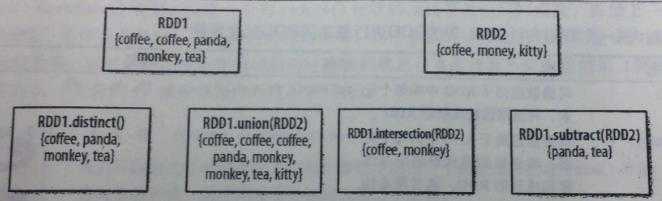
函数 | 用途 |
RDD1.distinct() | 生成一个只包含不同元素的新RDD。需要数据混洗。 |
RDD1.union(RDD2) | 返回一个包含两个RDD中所有元素的RDD |
RDD1.intersection(RDD2) | 只返回两个RDD中都有的元素 |
RDD1.substr(RDD2) | 返回一个只存在于第一个RDD而不存在于第二个RDD中的所有元素组成的RDD。需要数据混洗。 |
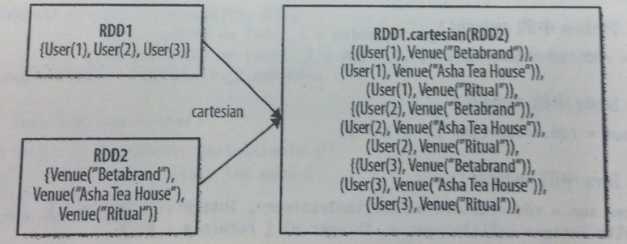
RDD1.cartesian(RDD2) | 返回两个RDD数据集的笛卡尔集 |
val rdd1=sc.parallelize(List(1,2));
val rdd2=sc.parallelize(List(1,2));
val rdd=rdd1.cartesian(rdd2);
println(rdd.collect().mkString("\n"));
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val results=rdd.reduce((x,y) =>x+y);
println(results);
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val results=rdd.fold(0)((x,y) =>x+y);
println(results);
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val results=rdd.fold(1)((x,y) =>x*y);
println(results);
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10));
val result=rdd.aggregate((0,0))(
(acc,value) =>(acc._1+value,acc._2+1),
(acc1,acc2) => (acc1._1+acc2._1, acc1._2+acc2._2)
)
val average=result._1/result._2;
println(average)
| 函数名 | 目的 | 示例 | 结果 |
| collect() | 返回RDD的所有元素 | rdd.collect() | {1,2,3,3} |
| count() | RDD的元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在RDD中出现的次数 | rdd.countByValue() | {(1,1), (2,1), (3,2) } |
| take(num) | 从RDD中返回num个元素 | rdd.take(2) | {1,2} |
| top(num) | 从RDD中返回最前面的num个元素 | rdd.takeOrdered(2)(myOrdering) | {3,3} |
| takeOrdered(num) (ordering) | 从RDD中按照提供的顺序返回最前面的num个元素 | rdd.takeSample(false,1) | 非确定的 |
| takeSample(withReplacement,num,[seed]) | 从RDD中返回任意一些元素 | rdd.takeSample(false,1) | 非确定的 |
| reduce(func) | 并行整合RDD中所有数据 | rdd.reduce((x,y) => x+y) | 9 |
| fold(zero)(func) | 和reduce()一样,但是需要提供初始值 | rdd.fold(0)((x,y) => x+y) | 9 |
| aggregate(zeroValue)(seqOp,combOp) | 和reduce()相似,但是通常返回不同类型的函数 | rdd.aggregate((0,0)) ((x,y) => (x._1+y,x._2+1), (x,y)=> (x._1+y._1,x._2+y._2) ) | (9,4) |
| foreach(func) | 对RDD中的每个元素使用给定的函数 | rdd.foreach(func) | 无 |
| 级别 | 使用的空间 | cpu时间 | 是否在内存 | 是否在磁盘 | 备注 |
MEMORY_ONLY | 高 | 低 | 是 | 否 | 直接储存在内存 |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | 序列化后储存在内存里 |
MEMORY_AND_DISK | 低 | 中等 | 部分 | 部分 | 如果数据在内存中放不下,溢写在磁盘上 |
MEMORY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 数据在内存中放不下,溢写在磁盘中。内存中存放序列化的数据。 |
DISK_ONLY | 低 | 高 | 否 | 是 | 直接储存在硬盘里面 |
val rdd=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10)).persist(StorageLevel.MEMORY_ONLY);
println(rdd.count())
println(rdd.collect().mkString(","));
val rdd=sc.parallelize(List(1.0,2.0,3.0,4.0,5.0));
println(rdd.mean());
原文:http://www.cnblogs.com/zhoudayang/p/5024425.html