1.配置host文件
2.建立hadoop运行账号
3.配置ssh免密码登录
4.下载并解压hadoop安装包
5.环境变量配置
export JAVA_HOME=/usr/local/jdk1.6 export HADOOP_HOME=/usr/hadoop export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
6.修改hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
7.配置core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop200:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hdfs/tmp</value> </property> </configuration>
fs.default.name:这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表
hadoop.tmp.dir:这里的路径默认是NameNode、DataNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。其默认位置在/tmp/{user}下。若此处不设置该属性,某些linux重启后,由于tmp目录会被清空,会发生文件无法找到的错误发生。
8.配置hdfs-site.xml
<configuration> <property> <name>dfs.name.dir</name> <value>file:/usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>file:/usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
9.配置mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>hadoop200:9001</value> </property> </configuration>
10.配置master
hadoop200
11.配置slave
hadoop201 hadoop202 hadoop203
12.向各节点复制hadoop
13.格式化namenode
14.启动hadoop
15.使用jps检查后台各进程是否正常启动
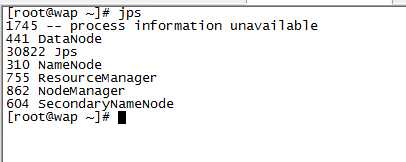
原文:http://www.cnblogs.com/jackgaolei/p/5001349.html