Shuffle和排序
MapReduce确保每一个reduce的输出都按键排序,系统执行排序的过程---------将map输出作为输入传给reduce--------称为shuffle
Shuffle过程是MapReduce的”心脏”,也被称为奇迹发生的地方
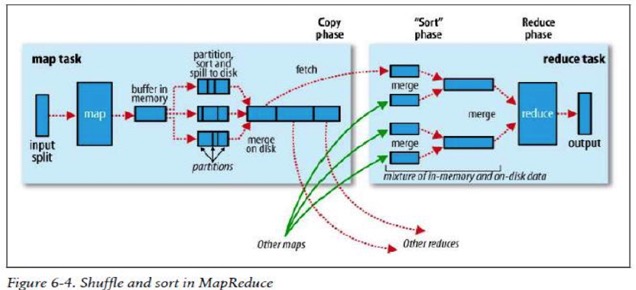
1. 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
2. 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
a)partition的意义在于可以分区管理,分类导出数据;例如男女,我需要分成两个文件,我就可以设置partition来区分,reduceTask至少2个来分别运行
b)运行conbiner的意义在于是map输出更紧凑,使得写到本地磁盘和传给reducer的数据更少
3. 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
补充:
原文:http://my.oschina.net/repine/blog/527833