http://onlinestatbook.com/stat_analysis/index.html
程序模拟网址

生成一个符合正态分布数据总体,保存到模板Population.py
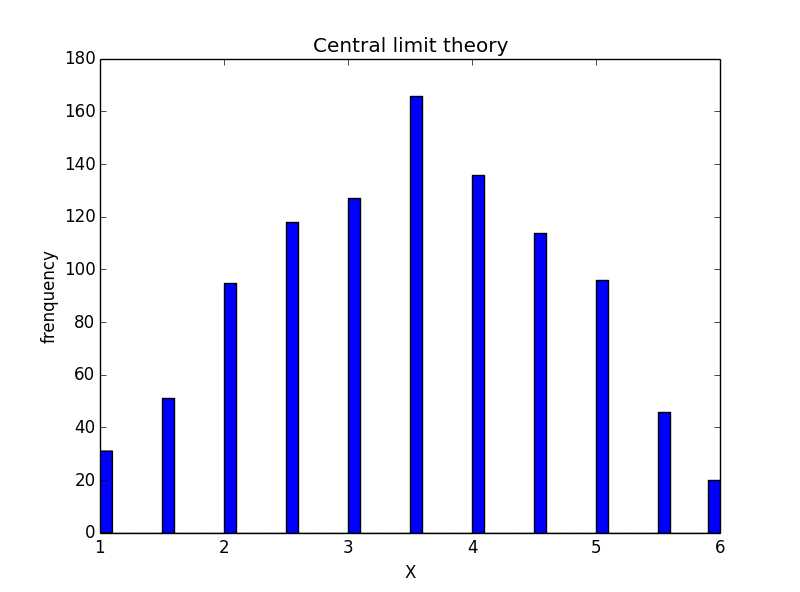
执行绘制直方图函数,检验样本数据是否符合正态分布,下图可见完全符合
>>> Draw_hist(population)
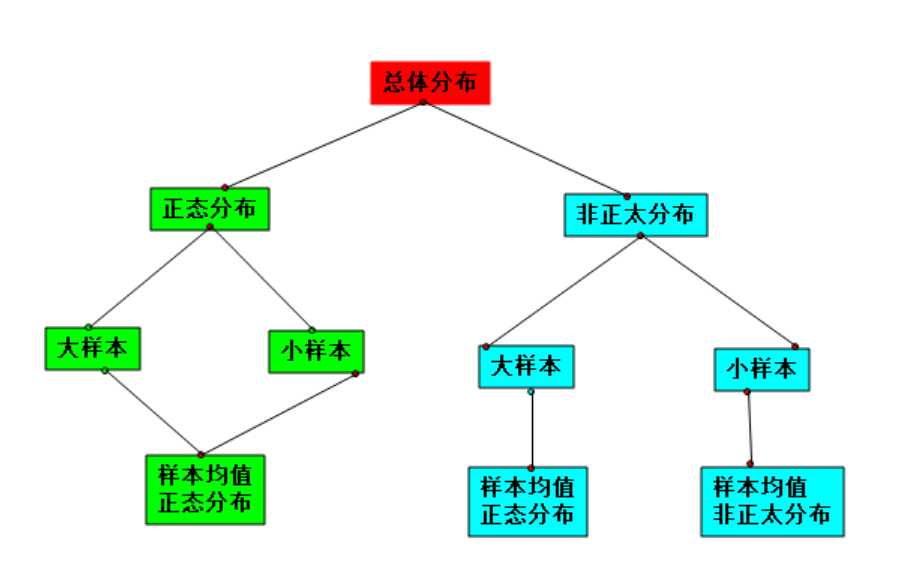
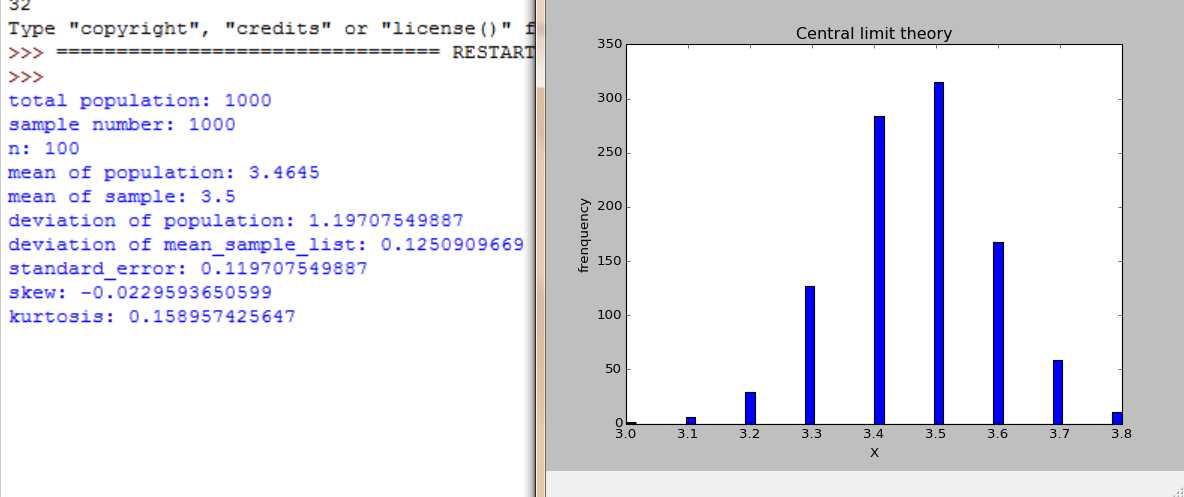
随着n=2,4,16,30,100, 样本数是大样本还是小样本,图形都服从正态分布,不同的是,随着n增大,分布范围缩小,标准差在缩小。
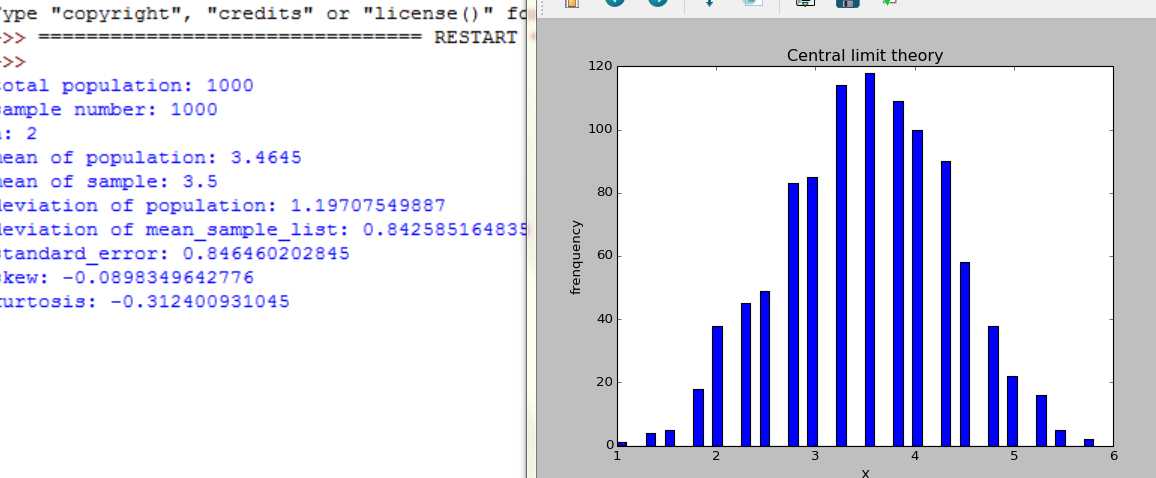
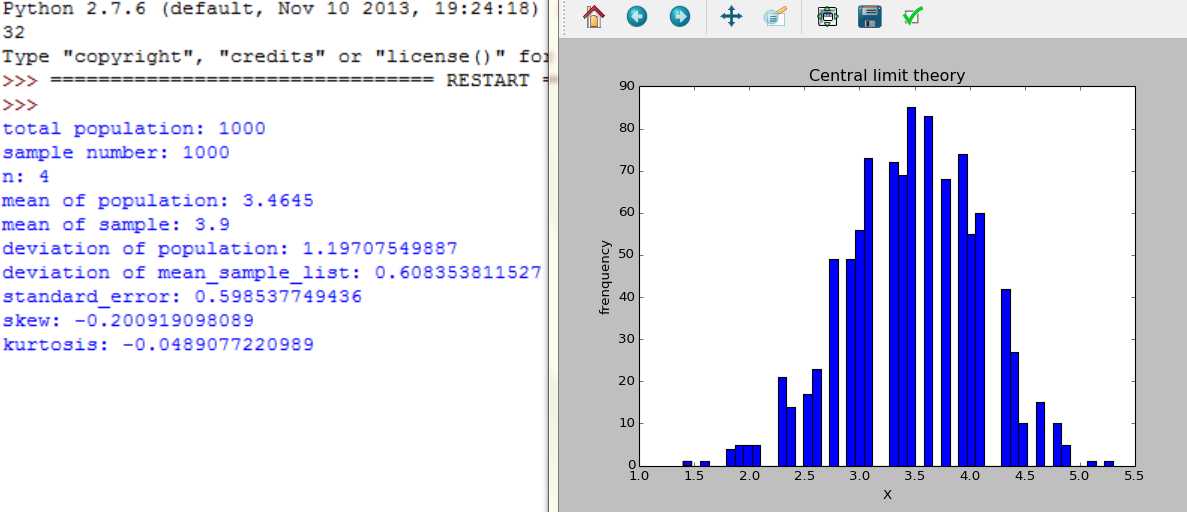
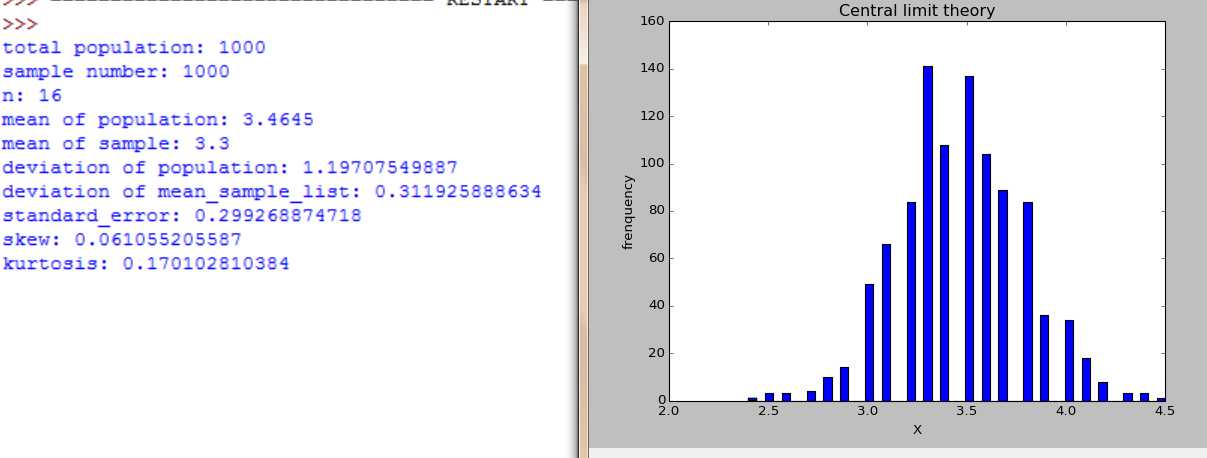
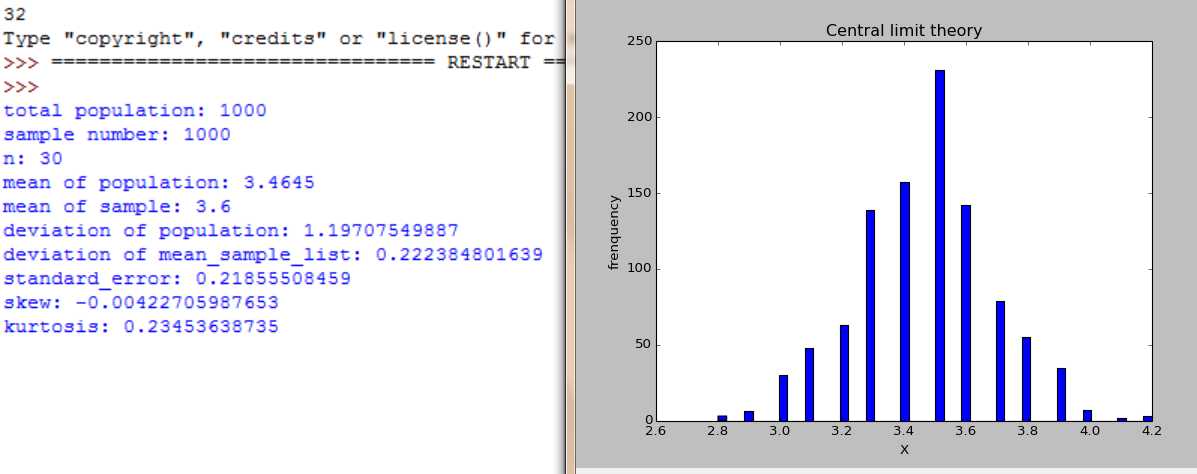
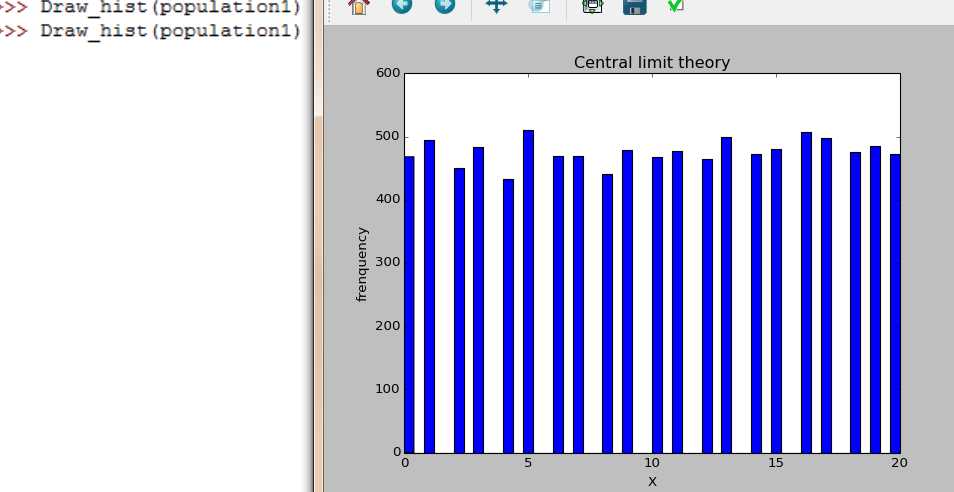
取一个非正太分布总体
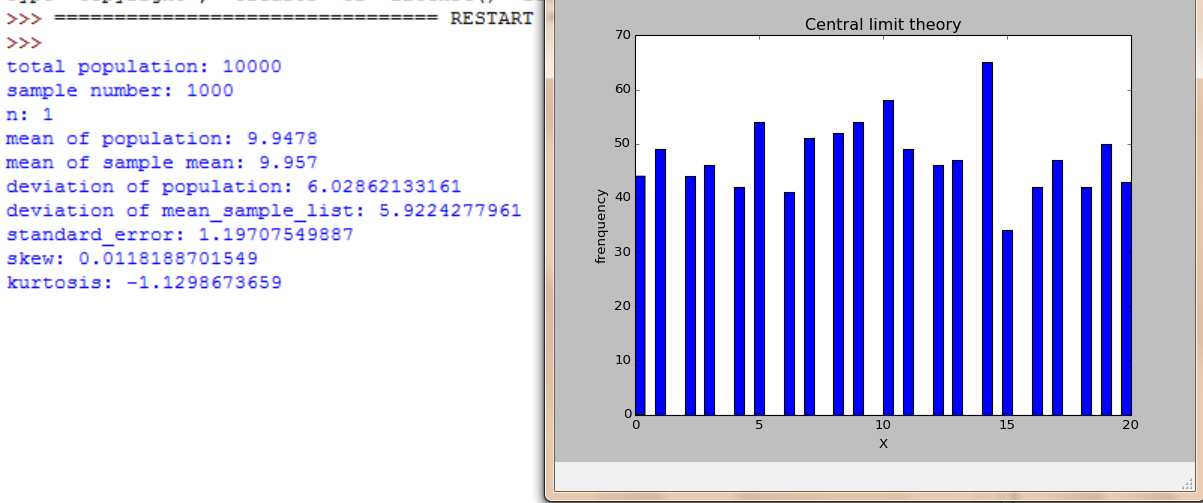
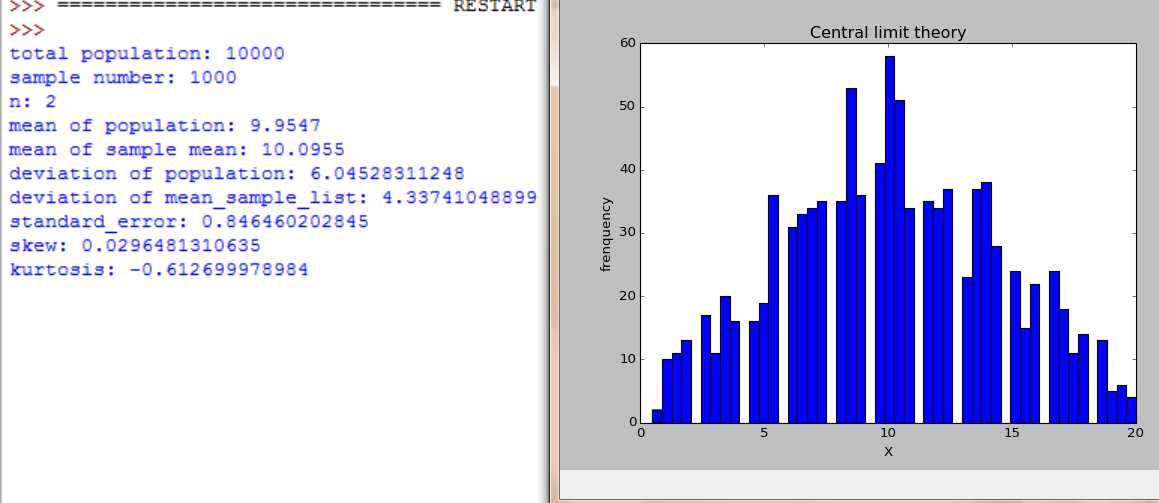
随着n=2,4,16,30,100, 样本数不断增大。大样本时图形都服从正态分布,小样本时,不服从正太分布。随着n增大,分布范围缩小,标准差在缩小。
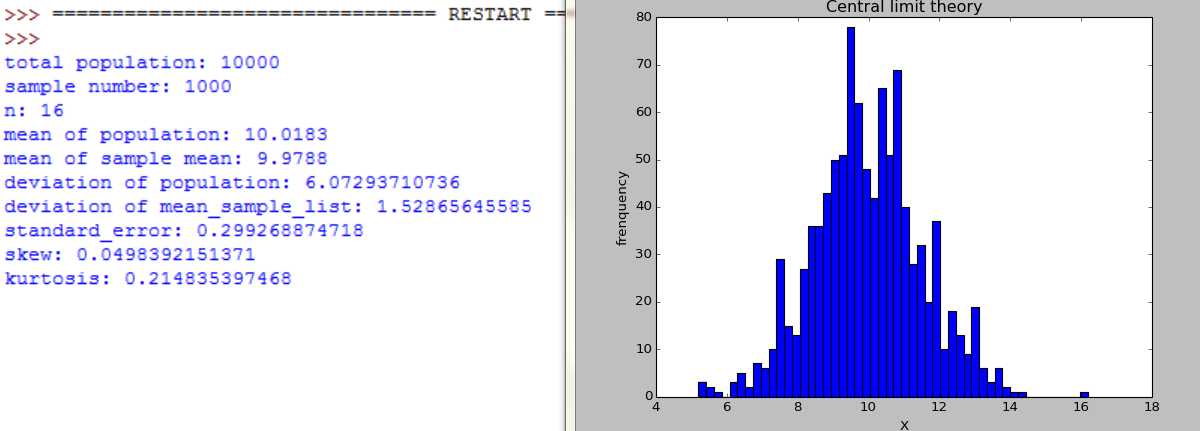
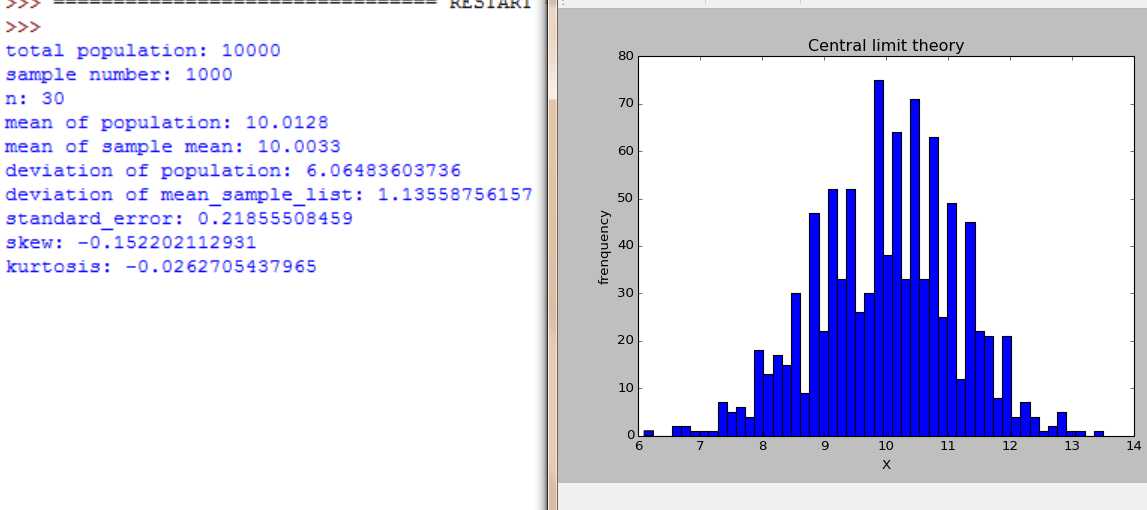
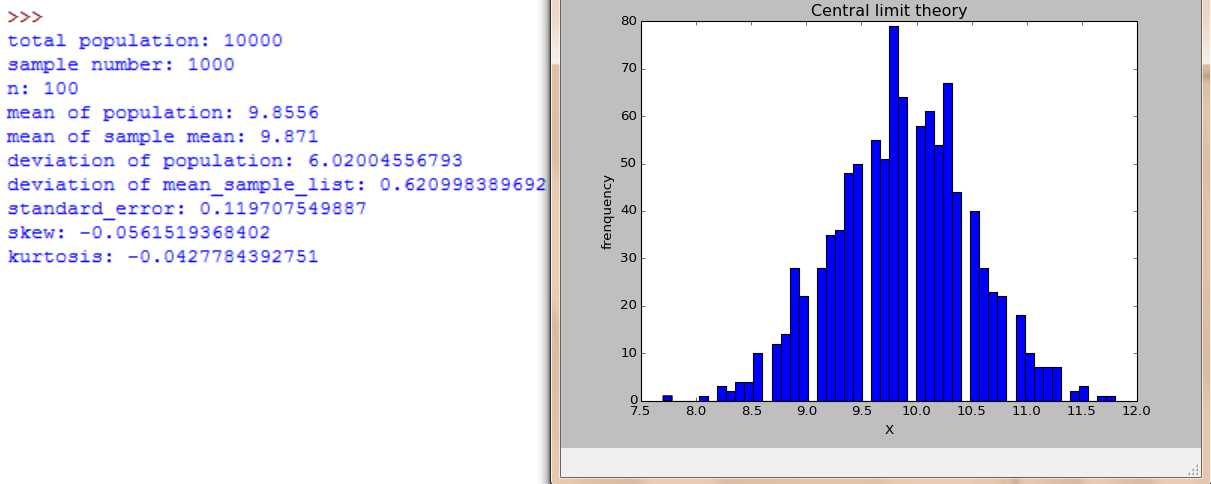
#coding=utf-8
#中心极限理论抽象,不好理解,可简化成两个骰子建模
#从均值mean,方差variance的总体中,抽取样本量为n的随机样本,当n充分大时(n>=30),样本均值服从均值
#为mean,方差为variance/n的正太分布
import math,random,os,statistics_functions,draw,time,pylab,Population,distribution_status
#生成一个真随机数
#骰子选数范围从1-6
number_list=[1,2,3,4,5,6]
#引用服从正太分布的总体
population=Population.population
number=len(population)
#n表示样本数,n=2表示丢两颗骰子,n=6表示丢6颗骰子
n=1
#有多少样本
sample_n=1000
def Random_number(population):
r=random.SystemRandom()
random_number=r.choice(population)
return random_number
#生成一个包含随机数的列表
#length表示列表内元素个数
def Random_list(n,population):
random_list=[]
for i in range(n):
random_number=Random_number(population)
random_list.append(random_number)
return random_list
#生成n个平均数
#元素是n个元素组成列表的平均数
def Mean_list(sample_n,n,population):
mean_list=[]
for i in range(sample_n):
random_list=Random_list(n,population)
mean=statistics_functions.Mean(random_list)
mean=round(mean,1)
mean_list.append(mean)
return mean_list
#返回不重复元素的列表
def List_noneRepeat(mean_list):
#去掉重复部分
list_noneRepeat=[]
for i in mean_list:
if i not in list_noneRepeat:
list_noneRepeat.append(i)
#print "list_noneRepeat:",list_noneRepeat
return list_noneRepeat
#频率计算函数
def Frequence(list_noneRepeat):
frequency=[]
#统计频率
for i in list_noneRepeat:
count=mean_list.count(i)
frequency.append(count)
return frequency
#时间测试
def time_test(n):
time3=time.time()
print time1
n
time4=time.time()
print time2
time_comsume=time4-time3
print time_comsume
def Draw_hist(mean_sample_list):
pylab.hist(mean_sample_list,50)
pylab.xlabel(‘X‘)
pylab.ylabel(‘frenquency‘)
pylab.title(‘Central limit theory‘)
pylab.show()
def Analyse(number,sample_n,n,mean_population,mean_mean_sample_list,deviation_population,\
deviation_mean_sample_list,standard_error,skew,kurtosis,mean_sample_list):
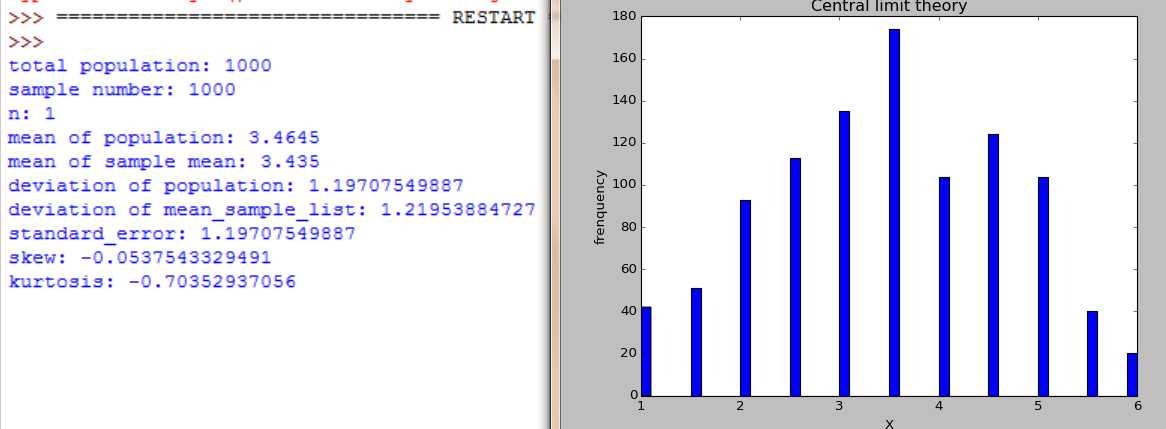
print "total population:",number
print "sample number:",sample_n
print "n:",n
print "mean of population:",mean_population
print "mean of sample mean:",mean_mean_sample_list
print "deviation of population:",deviation_population
print "deviation of mean_sample_list:",deviation_mean_sample_list
print "standard_error:",standard_error
print "skew:",skew
print "kurtosis:",kurtosis
Draw_hist(mean_sample_list)
#时间消耗测试
#总体
#population=Mean_list(n)
#总体的平均值
mean_population=statistics_functions.Mean(population)
#总体的标准差
deviation_population=statistics_functions.Deviation(population)
#所有样本平均数添加到一个列表中
mean_sample_list=Mean_list(sample_n,n,population)
#计算样本平均数的平均值
mean_mean_sample_list=statistics_functions.Mean(mean_sample_list)
#再计算这个列表中所有平均数的标准差
deviation_mean_sample_list=statistics_functions.Deviation(mean_sample_list)
#标准误
standard_error=(deviation_population*1.0)/math.sqrt(n)
#偏态和峰态
skew=distribution_status.Skew(mean_sample_list)
kurtosis=distribution_status.Kurtosis(mean_sample_list)
#输出结果,以便观察
Analyse(number,sample_n,n,mean_population,mean_mean_sample_list,deviation_population,\
deviation_mean_sample_list,standard_error,skew,kurtosis,mean_sample_list)
#引用不服从正太分布的总体
population1=Population.population1
number1=len(population1)
#总体的平均值
mean_population1=statistics_functions.Mean(population1)
#总体的标准差
deviation_population1=statistics_functions.Deviation(population1)
#所有样本平均数添加到一个列表中
mean_sample_list1=Mean_list(sample_n,n,population1)
#计算样本平均数的平均值
mean_mean_sample_list1=statistics_functions.Mean(mean_sample_list1)
#再计算这个列表中所有平均数的标准差
deviation_mean_sample_list1=statistics_functions.Deviation(mean_sample_list1)
#标准误
standard_error1=(deviation_population*1.0)/math.sqrt(n)
#偏态和峰态
skew1=distribution_status.Skew(mean_sample_list1)
kurtosis1=distribution_status.Kurtosis(mean_sample_list1)
#输出结果,以便观察
#Analyse(number1,sample_n,n,mean_population1,mean_mean_sample_list1,deviation_population1,\
#deviation_mean_sample_list1,standard_error1,skew1,kurtosis1,mean_sample_list1)
原文:http://www.cnblogs.com/biopy/p/4916940.html