朴素贝叶斯模型
1) X:一条未被标记的数据
2) H:一个假设,如H=X属于Ci类
根据贝叶斯公式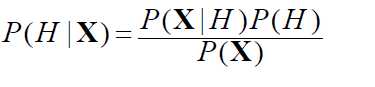
把X表示为(x1,x2,....xn) x1,x2,....xn表示X在各个特征上的值。
假设有c1,c2,c3...cm个类别。
那么这个对X的分类问题就可以转化为找出使P(ci|X)最大的类别ci作为分类结果
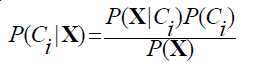
由于我们只需要找出P(ci|X)的相对最大值,那么即找出P(X|ci)P(ci)的最大值即可
N为整个训练集的个数
P(ci)=count(ci)/N
假设X的各个属性是相互独立的:
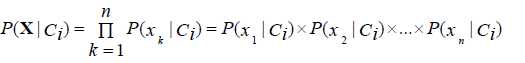
那么,如何求P(xi|cj)呢?
若第i个属性是离散型的,那么 P(xi|cj) = 所有分类为cj并且第i个属性值等于xi的数据个数/所有分类为cj的数据个数
若第i个属性是连续型的,假设这个连续型属性服从高斯分布:
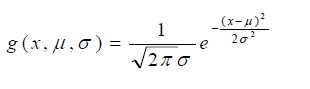
那么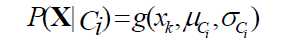
其中μci为所有数据类型为ci并且第i个属性值为xi的平均值
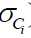 为所有数据类型为ci并且第i个属性值为xi的方差
为所有数据类型为ci并且第i个属性值为xi的方差
[数据挖掘课程笔记]Naïve Bayesian Classifier
原文:http://www.cnblogs.com/leeshum/p/4873346.html