该内容来自 http://stackoverflow.com/questions/30371030/understanding-cuda-profiler-output-nvprof
放在这里作为一个提示和总结
问题
I‘m just looking at the following output and trying to wrap my mind around the numbers:
==2906== Profiling result:
Time(%) Time Calls Avg Min Max Name
23.04% 10.9573s 16436 666.67us 64.996us 1.5927ms sgemm_sm35_ldg_tn_32x16x64x8x16
22.28% 10.5968s 14088 752.18us 612.13us 1.6235ms sgemm_sm_heavy_nt_ldg
18.09% 8.60573s 14088 610.86us 513.05us 1.2504ms sgemm_sm35_ldg_nn_128x8x128x16x16
16.48% 7.84050s 68092 115.15us 1.8240us 503.00us void axpy_kernel_val<float, int=0>(cublasAxpyParamsVal<float>)
...
0.25% 117.53ms 4744 24.773us 896ns 11.803ms [CUDA memcpy HtoD]
0.23% 107.32ms 37582 2.8550us 1.8880us 8.9556ms [CUDA memcpy DtoH]
...
==2906== API calls:
Time(%) Time Calls Avg Min Max Name
83.47% 41.8256s 42326 988.18us 16.923us 13.332ms cudaMemcpy
9.27% 4.64747s 326372 14.239us 10.846us 11.601ms cudaLaunch
1.49% 745.12ms 1502720 495ns 379ns 1.7092ms cudaSetupArgument
1.37% 688.09ms 4702 146.34us 879ns 615.09ms cudaFree
...When it comes to optimizing memory access, what are the numbers I really need to look at when comparing different implementations? It first looks like memcpy only takes 117.53+107.32ms (in both directions), but then there is this API call cudaMemcpy: 41.8256s, which is much more. Also, the min/avg/max columns don‘t add up between the upper and the lower output block.
Why is there a difference and what is the "true" number that is important for me to optimize the memory transfer?
EDIT: second question is: is there a way to figure out who is calling e.g. axpy_kernel_val (and how many times)?
回答
The difference in total time is due to the fact that work is launched to the GPU asynchronously. If you have a long running kernel or set of kernels with no explicit synchronisation to the host, and follow them with a call to cudaMemcpy, the cudaMemcpy call will be launched well before the kernel(s) have finished executing. The total time of the API call is from the moment it is launched to the moment it completes, so will overlap with executing kernels. You can see this very clearly if you run the output through the NVIDIA Visual Profiler (nvprof -o xxx ./myApp, then import xxx into nvvp).
The difference is min time is due to launch overhead. While the API profiling takes all of the launch overhead into account, the kernel timing only contains a small part of it. Launch overhead can be ~10-20us, as you can see here.
In general, the API calls section lets you know what the CPU is doing, while, the profiling results tells you what the GPU is doing. In this case, I‘d argue you‘re underusing the CPU, as arguably the cudaMemcpy is launched too early and CPU cycles are wasted. In practice, however, it‘s often hard or impossible to get anything useful out of these spare cycles.
总结
第一个======profiling result是说明GPU端的时间
第二个======API Calls 是说明CPU处测量的时间
原因就是kernel<<<>>>是异步执行的而cudaMemcpy是同步的(也就是阻塞的)对于下面的图而言,应该是gpu充分利用了,cudaMemcpy并不占用什么时间但是考虑其他的过程和总CPU耗时,可以知晓CPU端的耗时是很大的,所以有很大的优化空间来减少CPU的事情,或者说在CPU做同等工作的时候是不是能够更进一步利用GPU的性能。
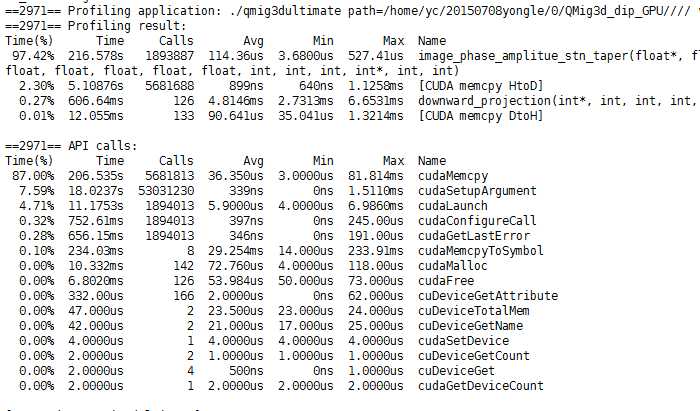
该程序总运行时间935s
J_)7BI@QKKRY[_2ZYM.png)
原文:http://www.cnblogs.com/reedlau/p/4846713.html