1、安装Python requests模块(通过pip):
环境搭建好了!
2、测试一下抓取URL的过程:
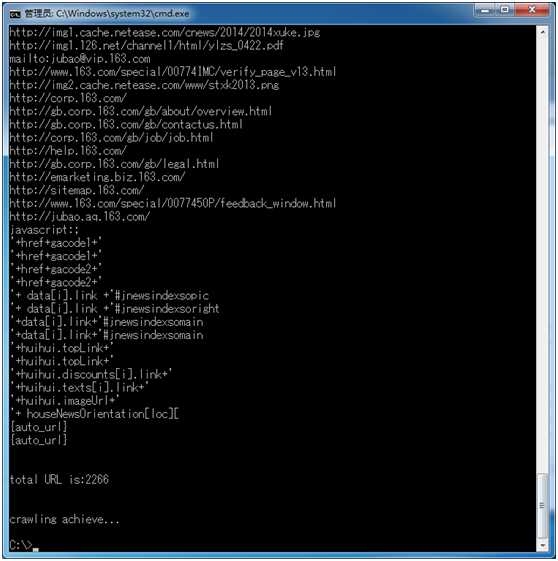
抓取出来的URL有JavaScript代码,正则上还有待更加完善,有兴趣的可以研究下~!
工具源代码:
#coding:utf-8
import sys
import re
import requests
#获取输入URL,并获取网页text
input = raw_input("please input URL format like this(http://www.baidu.com):")
print ‘input : %s‘ % input
r = requests.get(input)
data = r.text
#利用正则查找所有URL
link_list =re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\‘).+?(?=\‘)" ,data)
count = 0
for url in link_list:
file = open("c:\\test.txt", "a")
file.write(url+"\n")
count = count + 1
print url
print ‘\n‘
print ‘total URL is:‘ + str(count)
print ‘\n‘
print ‘crawling achieve...‘
file.close()
原文:http://www.cnblogs.com/milantgh/p/4844712.html