Scrapy 架構圖
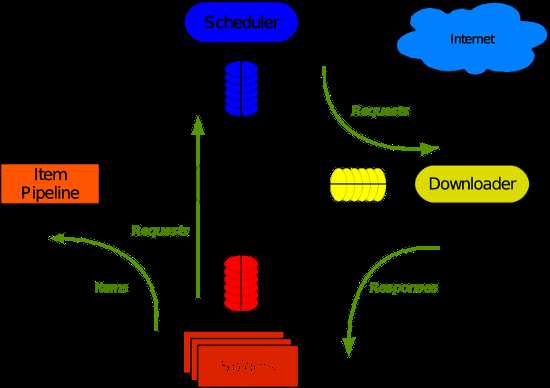
Spiders --> Scheduler --> Downloader --> 回到 Spiders,過濾抓到的資訊 --> 依 Item Pipeline 存抓到的資料
在寫 Spider 時心中要有這張圖,很重要!!
從 Scrapy Shell 開始吧~
這是一個 python 直譯器,可以動態顯示執行的結果。
Step
1. 開啟一個 Scrapy shell 抓以下網站的資料
scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"
2. 試一下吧~

In [1]: sel.xpath(‘//title‘) Out[1]: [<Selector xpath=‘//title‘ data=u‘<title>Open Directory - Computers: Progr‘>] In [2]: sel.xpath(‘//title‘).extract() Out[2]: [u‘<title>Open Directory - Computers: Programming: Languages: Python: Books</title>‘] In [3]: sel.xpath(‘//title/text()‘) Out[3]: [<Selector xpath=‘//title/text()‘ data=u‘Open Directory - Computers: Programming:‘>] In [4]: sel.xpath(‘//title/text()‘).extract() Out[4]: [u‘Open Directory - Computers: Programming: Languages: Python: Books‘] In [5]: sel.xpath(‘//title/text()‘).re(‘(\w+):‘) Out[5]: [u‘Computers‘, u‘Programming‘, u‘Languages‘, u‘Python‘]
上面是使用 Xpath 抓網頁的資訊,預設輸出使用 JSON 格式
3. 結束輸入exit
Xpath 不熟的話,可參考以下網址:
1. http://www.w3schools.com/XPath/
2. http://msdn.microsoft.com/zh-tw/library/ms256086(v=vs.110).aspx
練習 Xpath 的測試網站: http://www.freeformatter.com/xpath-tester.html
經驗談: 寫 Spider 之前,先用 Scrapy shell 測試抓的資料是否正確? 確認 Xpath 可正確抓到想要的資料後,在開始寫 Spider 會省下很多時間。
開始寫第一個 Spider 吧~
基本流程如下:
1. 建立一個新 Scrapy 專案
2. 定義你需要的 Item
3. 寫一個 Spider 抓資料
4. 寫一個 Item Pipeline 存抓到的資料
Step
1. 建立一個專案,名稱 tutorial
scrapy startproject tutorial
tutorial/
├── tutorial
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
2. 編輯 tutorial/tutorial/items.py 定義 Item
1 from scrapy.item import Item, Field 2 3 class DmozItem(Item): 4 title = Field() 5 link = Field() 6 desc = Field()
3. 建立 tutorial/tutorial/spiders/dmoz_spider.py 檔案,開始寫一個 Spider
1 from scrapy.spider import Spider 2 from scrapy.selector import Selector 3 4 from tutorial.items import DmozItem 5 6 class DmozSpider(Spider): 7 name = "dmoz" #給 Spider 取個名子 8 allowed_domains = ["dmoz.org"] #要抓的Domain 9 start_urls = [ 10 "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", #要抓的網址 11 "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" 12 ] 13 14 def parse(self, response): 15 sel = Selector(response) 16 sites = sel.xpath(‘//ul/li‘) 17 items = [] 18 for site in sites: 19 item = DmozItem() #之前 Step2 定義的 item 20 item[‘title‘] = site.xpath(‘a/text()‘).extract() #用 Xpath 抓指定的資料 21 item[‘link‘] = site.xpath(‘a/@href‘).extract() 22 item[‘desc‘] = site.xpath(‘text()‘).extract() 23 items.append(item) 24 return items
4. 執行 Spider,路徑必須在 tutorial/tutorial/spiders/ 才能執行
scrapy crawl dmoz -o items.json -t json
抓到的資料輸出成JSON格式的檔案,存在spiders/items.json
如果是抓中文的網站,會發現中文字變成像 \u4f60\u597d 的形式,原因是 python 預設編碼為 Utf-8,解決方法:
1. 使用線上的 Unicode 轉換程式
2. 自己寫一個簡單的PHP程式做轉換,可參考這篇
參考網址: 官方文件 http://doc.scrapy.org/en/latest/intro/tutorial.html
想知道一些更詳細的內容,可參考官方的文件。
原文:http://www.cnblogs.com/yijay/p/3629624.html